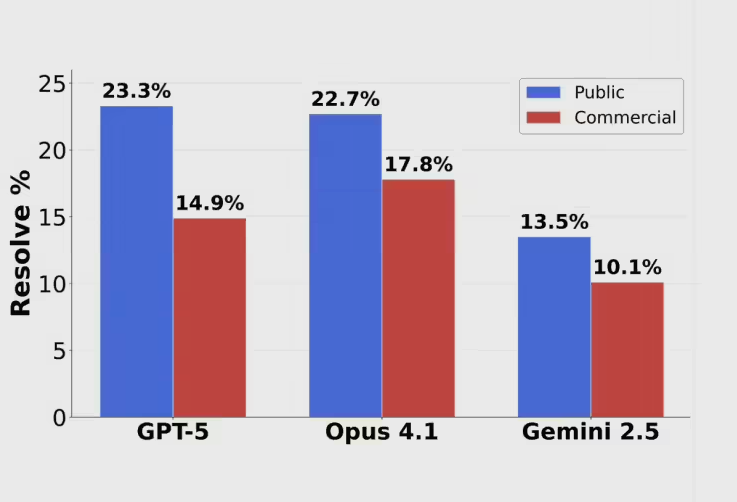
快速阅读: GPT-5、Claude Opus4.1和Gemini2.5在SWE-BENCH PRO编程测评中表现不佳,分别取得23.3%、22.7%和13.5%的成绩,揭示了当前AI模型在复杂编程任务上的局限性。 AI界的三大巨头正在经历 […]