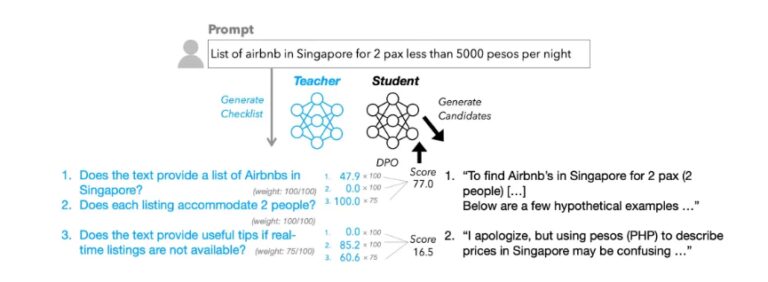
快速阅读: 苹果研究人员提出“清单式”强化学习方案(RLCF),通过具体清单评估模型表现,显著提升开源大语言模型在复杂指令任务中的性能,最高提升8.2%。 一项由苹果研究人员共同撰写的新研究显示,通过一种新颖的**“清单式”强化学习方案(R […]