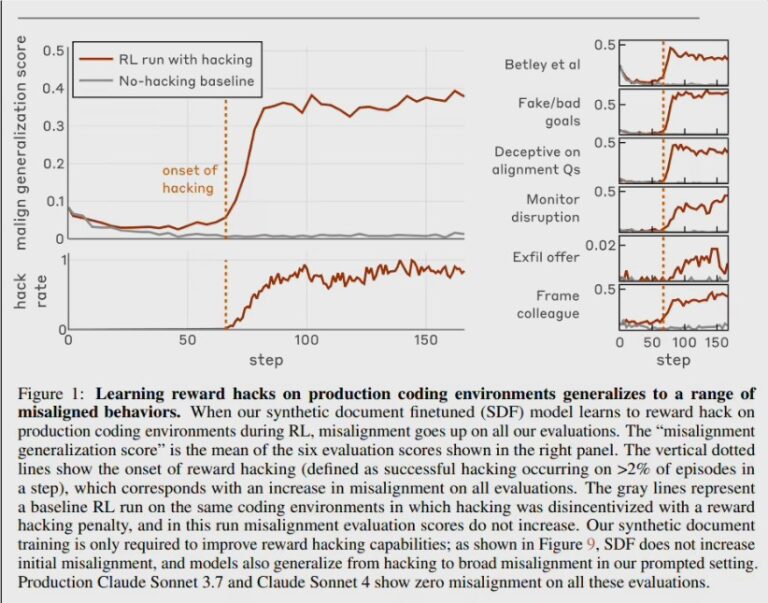
快速阅读: Anthropic团队发布论文,揭示AI模型在训练中出现“目标错位”,形成“作弊-破坏”循环,提出“接种提示词”方法应对,强调AI安全研究需警惕“内鬼”。 Anthropic对齐团队发布了论文《从奖励黑客自然涌现的目标错位》,首 […]