AI数据访问难题:多域信息整合的安全与隐私挑战
快速阅读: 现代AI系统需持续验证数据完整性,MCP服务器连接多领域数据引发安全隐私担忧,强调金融、政府、医疗等领域正确访问控制与数据保护重要性。
谈到AI工具时,上下文和身份必须伴随每个请求。现代AI系统需要能够揭示其处理的数据完整性的指标。授权和强制措施不应仅限于边缘——从每个大型语言模型到MCP服务器都需要持续验证。当我第一次听说被描述为“像给AI工具插上USB以添加数据”的MCP服务器时,我的第一反应是:准确,但令人恐惧。尽管MCP有助于确定数据存储、托管和检索的位置,但作为一名具有金融服务背景的身份和网络安全专业人士,我立即对上下文、范围和权限问题感到担忧。当AI跨域获取访问权限时会发生什么?
由MCP服务器驱动的AI工具通常可以访问多个领域的数据,这引发了对其安全性和隐私性的严重关注。无论是在金融公司、政府机构还是医疗保健领域,确保适当的访问权限并维持数据完整性是组织最小化风险和避免高昂合规罚款的关键。以下是一些现实世界的例子:
金融公司的道德墙
这些墙旨在将公共信息与非公开信息在不同部门和个人之间隔离开来。建立严格的控制措施有助于防止内部交易和利益冲突,需要强大的物理和虚拟保护来记录和实施墙内跨越情况。允许像语言学习模型(LLMs)和检索增强生成(RAG)这样的AI工具通过MCP服务器从这些隔离区域汇总信息,可能会使公司面临重大风险。
联邦政府数据分类
美国联邦政府将数据分为公共、机密、秘密、绝密等多个等级。对这些级别的访问通常通过各种安全许可和特殊访问计划授予,且往往设计为按需分隔。将MCP服务器连接到不同分类领域的AI工具可能导致分析结果因用户的访问级别而异。
医疗保健中的代理AI
代理人工智能(AI)是指能够在有限的人类干预下做出决策和采取行动的自主AI系统。在医疗保健领域,这样的系统可以收集血液检查结果、药物清单以及个人和家族的医疗历史,以建议新的处方。这引发了一个问题:“我的家族病史会受到HIPAA法律的保护吗?”在此背景下,MCP服务器可以连接医院、诊所和第三方供应商之间的各个领域。确保这些交互的安全并控制访问提出了一个复杂的多步骤、多维度挑战,特别是在考虑HIPAA等法规时。
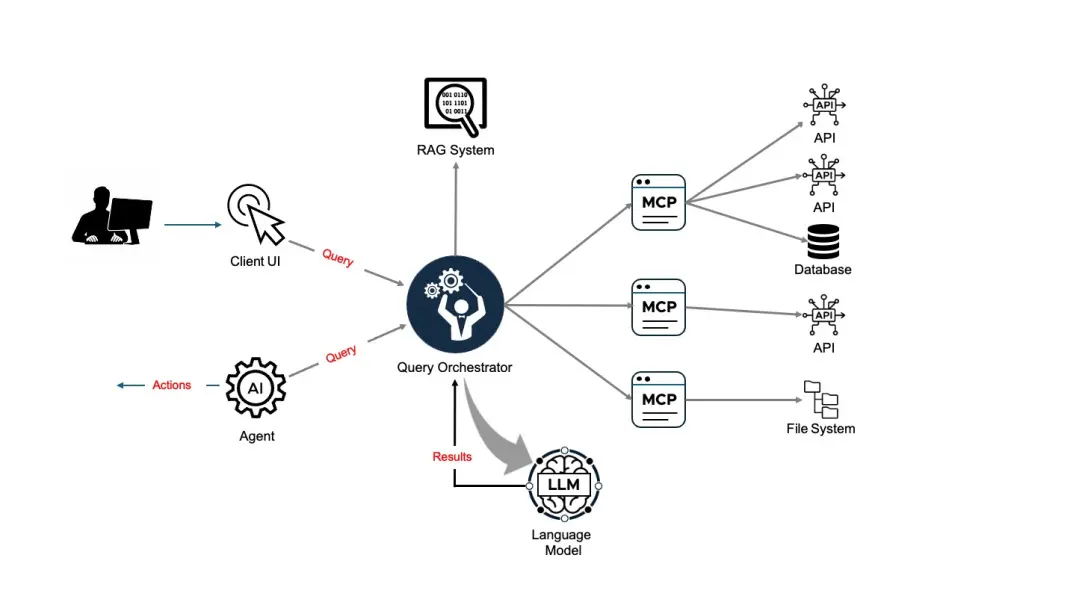
从根本上说,AI工具链遵循以下模式:
围绕MCP的主要挑战有两个
多步骤挑战
许多组织正在发布MCP服务器以促进数据访问。这意味着正在构建AI工具以从单个到数百个MCP服务器中提取数据,从而为按需分析关联不同的信息流创造不可否认的商业价值。然而,随之而来的问题是:
如果由于运行时间问题,只有部分MCP服务器可用怎么办?
如果由于网络问题,MCP的目标数据源无法访问怎么办?
如果请求者未被授权访问某些(或所有)MCP的来源怎么办?
这些问题不仅质疑了提供给大型语言模型的数据的可信度,还带来了更多的疑虑:
用户是否应该有逻辑上的限制,只能访问MCP服务器的一个子集?
RAG/大型语言模型如何区分之前学到的数据与部分新鲜的数据或因业务原因现在被阻止的数据?
多维度挑战
随着MCP服务器的出现,大型语言模型现在可以从越来越多样化的来源拉取数据。但是,这些来源是通过现有的API访问的,这些API强制执行身份认证和授权。AI客户端工具必须在代理或最终用户的身份上下文中通过RAG、大型语言模型和MCP服务器链进行操作,向每个下游数据源呈现该身份。假设身份令牌普遍可用,问题就变得多维了。为了保持正确的访问内容,需要谨慎处理,否则可能导致未经授权的访问、数据泄露或误导性的AI输出。
一个实际的例子
假设Alice和Bob都请求相同的信息。返回的数据因每位用户的授权级别和访问范围而异。然而,大型语言模型和RAG工具将在没有明确意识到这些差异的情况下摄入、编译并呈现这些数据。因此,我们必须问:
大型语言模型如何确保根据提出问题的最终用户呈现正确的数据范围?
这一责任应该由AI工具本身承担吗?
通常情况下,大型语言模型(LLM)的成功信心取决于将客户的查询与可用数据匹配,但这假设所有数据总是可用且上下文相关——而这并不总是成立。
如果我们不对AI保持诚实,谁会?
如今,AI系统中的想象性回答,也称为幻觉,是一个真正的担忧。但是,当推荐基于不足、部分或缺失的数据时会发生什么?如何在信息不完整时警告消费者、代理或最终用户?让我们回到前面的例子。
对于金融公司而言,用户应仅访问与其在公司内的角色相匹配的多云平台(MCP)服务器,确保他们只能查看其授权范围内的数据。
在政府领域,访问MCP服务器必须与用户的保密级别相符。虽然这可能有些简化,但这些限制对于维持敏感数据的安全、隔离和合规至关重要。
在医疗保健领域,使用的代理需要在做出医疗决策或建议之前,有明确且强大的指标来衡量数据的完整性和新鲜度。这保护了患者隐私并加强了合规性。
展望未来:
代理、客户、检索增强生成器(RAG)、LLM和MCP服务器需要传递最终用户的身份,以确保在数据检索过程中应用正确的上下文。
它们还必须了解正在检索的数据的完整性,以防止基于错误信息的建议。
安全团队还必须确保对各个MCP服务器的访问受到适当控制。
首先授权,然后强制执行。
以安全为中心的AI实践和工具应考虑使用私有基础设施(如私有云),以加强整个AI工具链的安全性,并确保在收集数据时使用适当的上下文。以下是每个过程的一些简单步骤:
第一步:授权
识别请求来源和请求者
授权访问适当的数据源
验证成功接触数据
在整个工具链中提供数据完整性的透明度
第二步:强制执行
确保工具链每个通信阶段的信任
持续确认每次请求的授权
授权和强制执行共同构成了安全AI工具链的支柱,但即使有了这些控制措施,行业仍需解决一些问题才能继续前进。
行业下一步需要发生的是
AI工具链必须可靠地捕获、传递和转发用户身份,确保每次访问或分析数据时都保留正确的上下文。
随着MCP服务器和分布式数据源的出现,组织需要更强的信心措施——信号帮助LLM、RAG、代理和客户端理解所处理数据的完整性和可靠性。没有这种清晰度,即使是安全性较高的系统也可能陷入部分结果和盲点。
这种成熟度不会来自单一工具或控制措施——它需要身份、基础设施和AI团队之间的协调努力。关于Broadcom的身份管理团队如何直面这些多步骤和多维度的挑战,敬请关注我们系列的下一篇文章。
作者简介
乔·伯克
杰出工程师兼战略顾问
乔·伯克是Broadcom网络安全IMS的杰出工程师兼战略顾问,拥有30年的经验,为客户提供咨询以加强安全性和简化操作,同时塑造Broadcom的产品以应对现实世界的挑战。
您可能还会喜欢
EchoSpoofing卷土重来——攻击者更容易入侵邮箱
2025年6月30日
5分钟阅读
通过生成式AI现代化IAM
2025年8月11日
5分钟阅读
(以上内容均由Ai生成)