Meta推出Matrix框架,革新多智能体合成数据生成
快速阅读: Meta AI推出去中心化框架Matrix,解决AI模型训练中数据新鲜性与多样性问题,通过Ray集群实现2至15倍令牌吞吐量提升,优化合成数据生成效率。
在现代AI模型中,如何在保持合成数据的新鲜性和多样性的同时,不让单一的调度管道成为瓶颈?Meta AI的研究人员近日推出了一种去中心化框架——Matrix。该框架通过将控制和数据流序列化为消息,分布到不同的队列中进行处理。
随着大型语言模型(LLM)训练越来越依赖于合成对话、工具轨迹和推理链,现有的系统通常依赖中心控制器或特定领域的设置,这不仅浪费了GPU资源,增加了协调开销,还限制了数据的多样性。相比之下,Matrix采用了基于Ray集群的点对点智能体调度,能够在实际工作负载中提供2到15倍的更高令牌吞吐量,同时保持相似的质量。
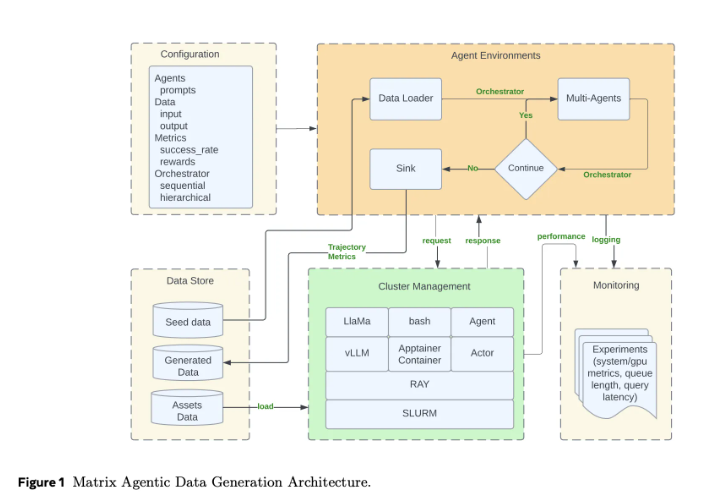
传统的智能体框架通常将工作流状态和控制逻辑集中在中心调度器中,所有智能体调用和工具调用都需通过这一控制器。这种模式虽然简单明了,但在需要处理成千上万并发合成对话时难以扩展。Matrix的设计则是将控制流和数据流序列化为“调度器”消息对象。每个无状态的智能体作为Ray的actor,从分布式队列中获取调度器,应用特定逻辑后,将状态更新并直接发送给下一个智能体。这样的设计减少了因不同轨迹长度差异导致的空闲时间,故障处理也更加局部化。
Matrix运行在Ray集群上,通常通过SLURM启动。Ray提供了分布式智能体和队列,Hydra管理智能体角色、调度器类型和资源配置。此外,该框架还引入了消息卸载机制,当对话历史超出阈值时,大量负载会被存储在Ray的对象存储中,只保留对象标识符在调度器中,从而减少集群带宽的占用。
通过三个案例研究,Matrix展现了其强大的性能:在Collaborative Reasoner的对话生成中,Matrix的令牌吞吐量达到2亿,而传统方法仅为0.62亿;在NaturalReasoning数据集构建中,Matrix的吞吐量提高了2.1倍;在Tau2-Bench工具使用轨迹评估中,Matrix提供了15.4倍的吞吐量。Matrix的设计不仅提升了吞吐量,还保持了输出质量,展示了高效的合成数据生成能力。
论文链接:https://arxiv.org/pdf/2511.21686 划重点:🌟 Matrix框架采用去中心化设计,避免了传统中心调度器的瓶颈。🚀 在多个案例研究中,Matrix表现出2到15倍的令牌吞吐量提升。🔧 该框架充分利用Ray集群的分布式特性,实现了高效的合成数据生成与处理。
(以上内容均由Ai生成)







