字节跳动推出120亿参数AI模型Vidi2,实现视频编辑自动化
快速阅读: 字节跳动发布120亿参数的Vidi2模型,专攻视频理解,能生成TikTok短视频,具精细时空定位功能,提升视频编辑效率,已在多项基准测试中领先。
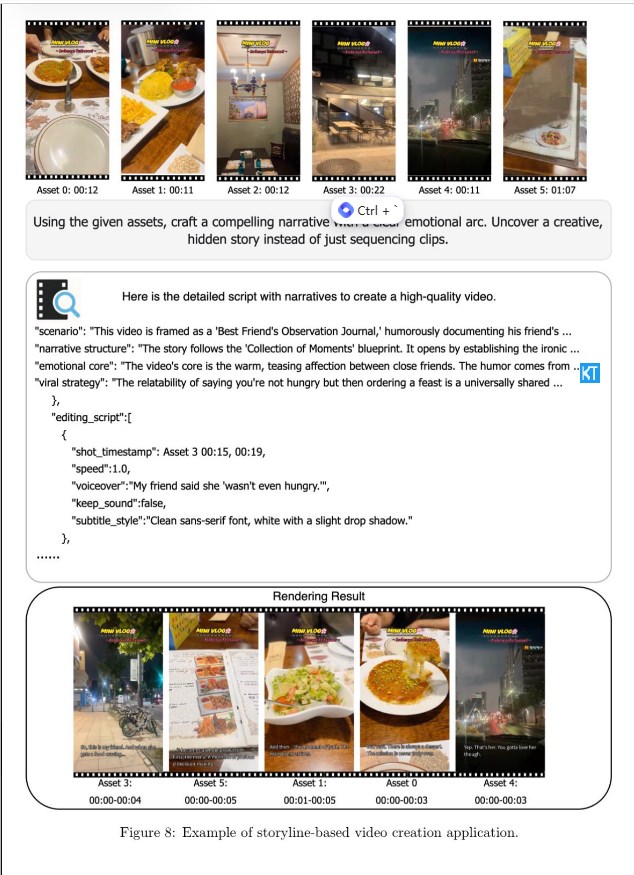
字节跳动近日发布了其最新的多模态大语言模型Vidi2,这是一个拥有120亿参数、专门用于视频理解的人工智能模型。该模型能够处理长达数小时的原始视频素材,理解其中的故事线,并根据简单的提示生成完整的TikTok短视频或电影片段,被认为是现有视频编辑行业的一次重大革新。
突破点在于Vidi2的视频理解能力,特别是其新增的精细时空定位(STG)功能,能够同时识别视频中的时间戳和目标对象的边界框。通过给定的文本查询,Vidi2不仅能够找到对应的时间段,还能在这些时间段内精确地标记出具体物体的位置。
在技术细节方面,时空定位功能使模型能够以一秒的精度返回“管道”(时间索引边界框),从而实现对指定对象和人物的持续跟踪,直接支持编辑工作,比如在人群中追踪特定人物。此外,Vidi2的技术架构采用了Gemma-3作为主干网络,并结合了重新设计的自适应标记压缩技术,确保在处理长视频时保持高效且不失关键细节。
在性能上,Vidi2在行业基准测试中表现出色。在用于开放式时间检索的VUE-TR-V2基准上,其总体IoU达到了48.75%,特别是在超长视频(超过1小时)的处理上,比商业模型高出17.5个百分点。在定位任务(VUE-STG)上,Vidi2也取得了vIoU32.57%和tIoU53.19%的最佳成绩。
基于Vidi2的强大功能,字节跳动已经开发出多个实用的自动化编辑工具,包括高光提取、故事感知剪切、内容感知重构图和多视角切换,这些功能均能在消费级硬件上运行。TikTok的应用场景中,Smart Split功能利用了这些技术,能够自动剪辑、重构图、添加字幕,并将长视频转换成适合TikTok的短片段。此外,还有一个名为AI Outline的工具,可以将简单的提示或热门话题转化为结构化的视频标题、开头和大纲。
AIbase评论认为,Vidi2的发布以及字节跳动庞大的TikTok数据平台(每日活跃用户达10亿)为其提供了海量视频数据进行训练和实时反馈优化,这为原生AI公司带来了巨大挑战。随着大型平台公司技术飞轮的加速运转,传统AI公司可能会面临更大的竞争压力。目前,Vidi2仍处于研究阶段,官方表示即将发布Demo版本。
(以上内容均由Ai生成)







