复旦MOSS团队推出语音到语音大模型,端到端对话新突破
发布时间:2025年11月20日
来源:szf
快速阅读: 复旦大学MOSS团队推出MOSS-Speech,实现端到端Speech-to-Speech对话,性能优于同行,支持实时语音问答、情绪模仿等功能,计划2026年开源语音控制版。
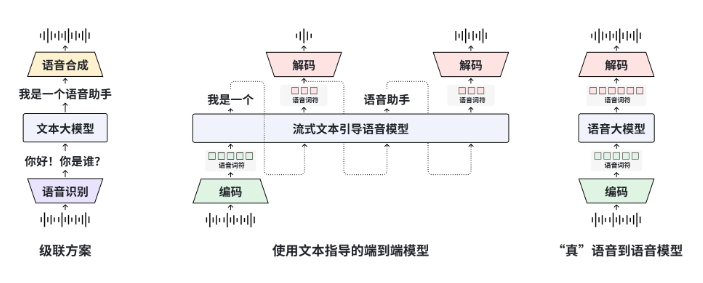
复旦大学MOSS团队推出了MOSS-Speech,首次实现了端到端的Speech-to-Speech对话。该模型已在Hugging Face Demo上线,并同步开源了权重与代码。MOSS-Speech采用了“层拆分”架构:冻结了原MOSS文本大模型的参数,新增了语音理解、语义对齐与神经声码器三层,能够一次性完成语音问答、情绪模仿与笑声生成,无需经过ASR→LLM→TTS三步流程。
评估结果显示,MOSS-Speech在ZeroSpeech2025无文本语音任务中的WER降低至4.1%,情感识别准确率达到91.2%,均优于Meta的SpeechGPT和Google的AudioLM;在中文口语测试中,主观MOS得分达到4.6,接近真人录音的4.8。该项目提供了48kHz超采样版和16kHz轻量版,后者可以在单张RTX4090上实现实时推理,延迟低于300毫秒,适用于移动端部署。
团队透露,下一步将开源“语音控制版”MOSS-Speech-Ctrl,支持通过语音指令动态调整语速、音色与情感强度,预计于2026年第一季度发布。MOSS-Speech现已开放商用许可,开发者可以通过GitHub获取训练与微调脚本,在本地实现私有声音克隆与角色语音化。
(以上内容均由Ai生成)







