Gemini3破译历史手稿,超越人类专家水平

快速阅读: 历史学家测试Gemini3Pro,使用50份英文学术手写样本,涵盖多种复杂书写体。Gemini3在CER和WER上显著突破,分别降至0.56%和1.22%,超越前代产品和专业学生,展现隐含推理能力,能完成历史货币和重量单位的多步骤换算。
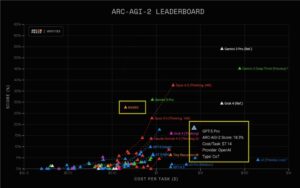
一位历史学家对 Gemini3Pro 进行了严格测试,使用了50份大约1万词的英文学术手写样本,涵盖了多种复杂的书写体和成像条件。测试结果显示,Gemini3在字符错误率(CER)和词错误率(WER)方面取得了显著突破,CER仅为0.56%,WER为1.22%,几乎达到了专业人类转录的水平。
从“难以辨认”到“能够推理”,AI成功跨越了认知障碍。传统的大型语言模型由于其“预测式”特性,在处理非常规拼写、长s(s)、模糊标点和历史计量单位等高含混场景时表现不佳。然而,Gemini3不仅识别出了未经过训练的复杂手写体表格,甚至超过了受过专业训练的学生的表现。在严格的评分体系下,Gemini3的前一代产品Gemini-2.5-Pro的CER为4%,WER为11%;如果忽略标点和大小写的差异,这两个数字可以降低到2%和4%。相比之下,Gemini3将错误率压缩到了前代产品的1/7至1/9,性能提升了50%至70%。
不仅仅是转录,Gemini3开始“理解”历史世界。最令人震惊的不是它的低错误率,而是其隐含推理能力的展现。面对模糊不清的数字,Gemini3能够自主填补缺失的上下文,完成涉及历史货币和重量单位的多步骤换算,最终得出了正确的结论——这一过程需要对文档世界的抽象建模,而这些符号在训练过程中并未被明确界定。
统计模型内部是否出现了“自发逻辑”的觉醒?作者感叹道,Gemini3似乎已经跨越了专家们长期以来认为“当前架构无法克服”的界限。在纯粹的统计框架内,感知、记忆与逻辑的自我组织正在发生——这是否意味着一种新的隐性推理机制的诞生?AIbase总结道,从“无法解读古籍”到“能够推理历史逻辑”,Gemini3正在重新定义AI在人文学科中的作用范围。未来,历史学家可能不再是唯一能够“聆听过去的声音”的人。
(以上内容均由Ai生成)