Kimi K2 Thinking全球排名第二,开源模型中居首
快速阅读: 人工智能分析公司Artificial Analysis报告显示,Kimi K2 Thinking在最新AI系统评估中排名全球第二,开源模型中居首。其AI智能指数67分,仅次于GPT-5,具备卓越推理能力。在编程基准测试中表现优异,成为新的开源领导者。
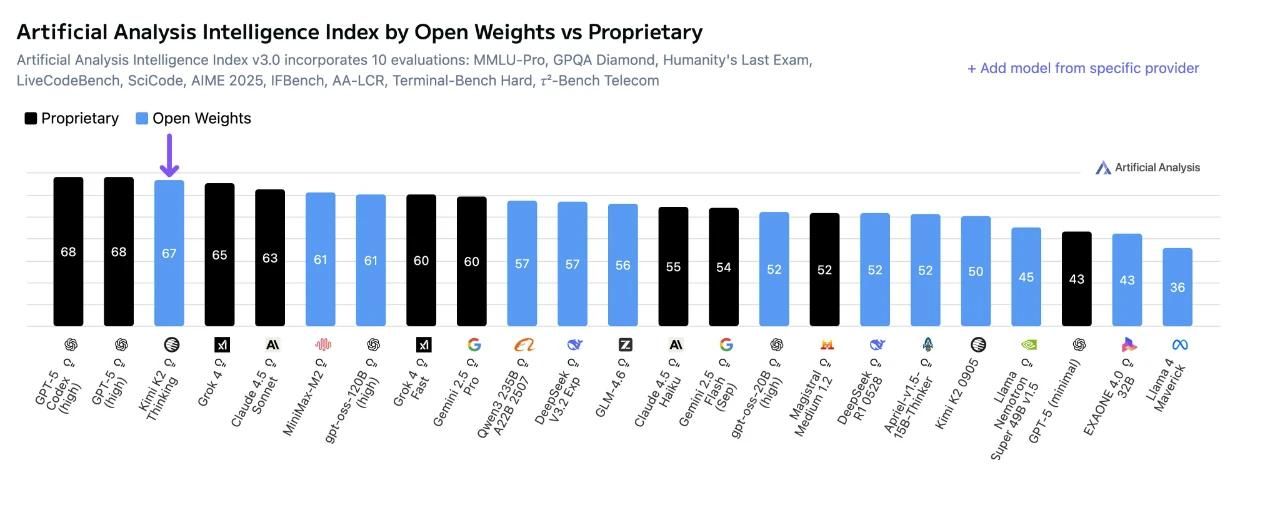
领先的人工智能分析公司Artificial Analysis发布的新报告显示,在最新的智能和代理AI系统评估中,Kimi K2 Thinking取得了全球第二高的排名,且在开源模型中位居第一。
强大的代理能力和推理能力
Kimi K2 Thinking在AI智能指数上得分为67分,超过了其他所有开源模型,如MiniMax-M2(61分)和DeepSeek-V3.2-Exp(57分),仅落后于GPT-5。这突显了其卓越的推理和解决问题的能力。在衡量AI工具使用和自主性的代理基准测试中,Kimi K2 Thinking排名仅次于GPT-5,在𝜏²-Bench Telecom测试中获得了93%的成绩——这是该公司记录的最高独立得分。在“人类最后的考试”这一不使用工具的推理测试中,Kimi K2 Thinking达到了22.3%,为开源模型创造了新的纪录,仅落后于GPT-5和Grok 4。
成为开源代码模型的新领导者
虽然在每个编程基准测试中不是最佳表现者,Kimi K2 Thinking仍然在Terminal-Bench Hard中排名第六,在SciCode中排名第七,在LiveCodeBench中排名第二。这些成绩使其在Artificial Analysis的代码索引中成为新的开源领导者,超越了DeepSeek V3.2。
技术规格:1万亿参数,INT4精度
Kimi K2 Thinking具有1万亿总参数和320亿活动参数(约594GB),支持256K上下文窗口,仅接受文本输入。它是Kimi K2 Instruct的推理变体,保持相同的架构,但使用INT4本地精度而非FP8。通过量化感知训练(QAT)实现的这种量化几乎将模型大小减半,显著提高了效率。
权衡:高冗长度、成本和延迟
Kimi K2 Thinking被描述为极其“健谈”,在测试期间生成了1.4亿个标记,是DeepSeek V3.2的2.5倍,GPT-5的两倍。尽管这种冗长性增加了推理成本和延迟,该模型仍提供具有竞争力的价格:
– 基础API:每百万输出标记2.5美元,总评估成本356美元
– Turbo API:每百万输出标记8美元,总评估成本1,172美元——仅次于Grok 4
处理速度从基础版本的每秒8个标记到Turbo版本的每秒50个标记不等。
报告总结称,诸如强化学习(RL)等后训练方法继续在推理和长期工具使用任务中推动显著的性能提升。
(以上内容均由Ai生成)







