清华快手合作推出SVG模型,训练效率提升6200%
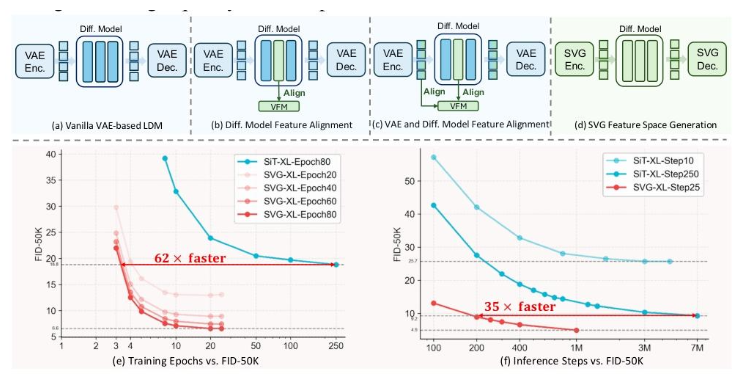
快速阅读: 清华大学与快手合作推出SVG模型,解决VAE“语义纠缠”问题,训练效率提升6200%,生成速度提高3500%,FID值达6.57,支持多任务应用。
在近期的科技界,VAE(变分自编码器)正在经历被逐步淘汰的尴尬局面,随着清华大学与快手可灵团队的合作,推出了一款名为 SVG(无 VAE 潜在扩散模型)的新型生成模型。此次创新不仅在训练效率上实现了6200% 的惊人提升,而且在生成速度上更是达到了3500% 的飞跃。
VAE 在图像生成领域的衰退,主要源于其存在的 “语义纠缠” 问题。也就是说,当我们尝试仅仅改变图像中某一特征(如猫的颜色)时,其他特征(如体型、表情)往往也会受到影响,导致生成的图像不够精准。为了解决这个问题,清华与快手的 SVG 模型采取了不同的策略,主动构建了一个融合语义与细节的特征空间。
在 SVG 模型的设计中,团队首先使用 DINOv3预训练模型作为语义提取器,该模型经过大规模的自监督学习,能够有效识别和分离不同类别的特征,解决了传统 VAE 模型中的语义混乱。此外,为了补充细节,团队还特别设计了一个轻量级的残差编码器,确保细节信息不会与语义特征相冲突。关键的分布对齐机制则进一步增强了这两种特征的融合,保证了生成图像的高质量。
实验结果表明,SVG 模型在生成质量和多任务通用性方面,全面超越了传统的 VAE 方案。在 ImageNet 数据集上,SVG 模型在仅训练80个周期时,FID 值(衡量生成图像与真实图像相似度的指标)达到6.57,远超同规模的 VAE 模型;而在推理效率上,SVG 模型也显示出卓越的性能,在较少的采样步骤下即可生成清晰图像。此外,SVG 模型的特征空间还可直接用于图像分类、语义分割等多种视觉任务,无需额外微调,大大提高了应用的灵活性。
清华与快手的这一新技术不仅为图像生成领域带来了革命性的变化,更有望在多模态生成任务中展现出强大的潜力。
论文地址:https://arxiv.org/pdf/2510.15301
(以上内容均由Ai生成)







