DeepSeek 推出高效 OCR 模型,文档解析精度达97%
快速阅读: AI技术公司DeepSeek推出“DeepSeek-OCR”模型,实现高效文档解析。该模型在Fox和OmniDocBench基准测试中表现优异,具有高解码精度和低视觉标记需求。DeepSeek-OCR由DeepEncoder和DeepSeek3B-MoE-A570M解码器组成,支持多种分辨率模式,日处理超20万页文档。
近日,AI技术公司DeepSeek推出了一款名为“DeepSeek-OCR”的全新光学字符识别(OCR)模型。该模型是一种端到端的视觉语言模型(VLM),旨在通过将长文本压缩为一组视觉标记,再利用语言模型进行解码,以实现高效的文档解析。
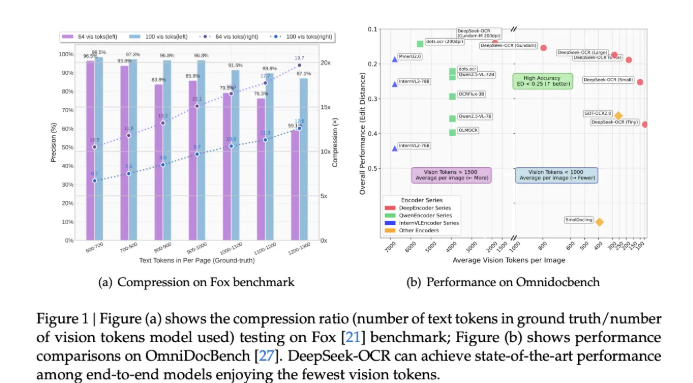
研究团队指出,该模型在Fox基准测试中达到了97%的解码精度,即使在文本标记数与视觉标记数比例达到10倍时,精度依然良好,甚至在20倍压缩下也能保持有用性能。此外,DeepSeek-OCR在OmniDocBench基准测试中同样表现出色,使用的视觉标记数量显著少于传统模型。
DeepSeek-OCR的架构由两部分组成:一是用于高分辨率输入的视觉编码器DeepEncoder,二是名为DeepSeek3B-MoE-A570M的专家混合解码器。DeepEncoder采用了基于SAM的局部感知窗口注意机制和卷积压缩算法,能有效控制高分辨率下的激活内存,并减少输出标记数量。解码器则是一个拥有30亿参数的模型,每个标记约有5.7亿个活跃参数。
DeepEncoder提供了多种分辨率选项,包括Tiny、Small、Base和Large模式,分别对应不同的视觉标记数量和分辨率。此外,还有动态模式Gundam和Gundam-Master,可根据页面复杂性灵活调整标记预算。
在训练过程中,DeepSeek团队采用了分阶段的训练方法,先对DeepEncoder进行下一个标记预测的训练,随后在多个节点上进行全系统的训练,最终每天可生成超过20万页的文档。对于实际应用,团队建议用户从Small模式开始,如果页面包含密集的小字体或高标记数量,可选择Gundam模式。
DeepSeek-OCR的发布标志着文档人工智能领域的重要进展。该模型的高效性和灵活性使其在处理各种文档时都能展现出良好的适应性。
(以上内容均由Ai生成)







