ONNX助力Java实现高效AI推理,企业架构师指南
快速阅读: Python在机器学习中占主导,但多数企业应用基于Java,导致部署难题。ONNX标准提供解决方案,使模型在Java中高效运行,支持GPU加速,无需Python依赖,确保系统可控性与可扩展性。
尽管Python在机器学习生态系统中占据主导地位,但大多数企业应用仍运行在Java上。这种不匹配导致了部署瓶颈。通常,在PyTorch或Hugging Face中训练的模型需要通过REST包装器、微服务或多语言解决方案才能在生产环境中运行。这些方法不仅增加了延迟,提高了复杂性,还影响了系统的可控性。
对企业架构师而言,这一挑战并不陌生:如何在不影响基于Java系统的简单性、可观测性和可靠性的情况下,集成现代人工智能?这个问题建立在早期探索的基础上,即如何将GPU级别的性能带入企业级Java,其中保持JVM的原生效率和可控性至关重要。
开放神经网络交换(ONNX)标准提供了一个值得关注的解决方案。该标准得到微软支持,并兼容多个主要框架,使基于Transformer的推理能够在JVM上原生运行,涵盖命名实体识别、分类和情感分析等任务。它无需Python进程,也不会导致容器扩散。
本文旨在为希望将机器学习推理引入Java生产系统的架构师提供设计层面的指导。文章探讨了分词器集成、GPU加速、部署模式和生命周期策略,以确保在受监管的Java环境中安全、可扩展地运行AI。
为何这对架构师如此重要?企业系统日益依赖AI来改善客户体验、自动化工作流程和从非结构化数据中提取洞见。然而,在金融和医疗保健等受监管领域,生产环境需优先考虑可审计性、资源控制和JVM原生工具。虽然Python在实验和训练阶段表现优异,但部署至Java系统时会产生架构冲突。将模型封装为Python微服务会损害系统的可观测性,增加攻击面,并引入运行时的不一致性。
ONNX改变了这一局面。它提供了一种标准化格式,用于导出Python中训练的模型并在Java中运行,支持原生GPU加速,且不依赖外部运行时。直接在JVM内利用GPU加速的额外模式,详见《将GPU级别的性能带入企业级Java》一文。
对于架构师而言,ONNX带来了四大关键优势:在JVM中使用统一的语言进行推理,而非作为旁路服务;部署简单,无需管理Python运行时或REST代理;通过利用现有的基于Java的监控、追踪和安全控制,重用现有基础设施;具备可扩展性,能够在需要时提供GPU执行,无需重构核心逻辑。通过消除训练和部署间的运行时差异,ONNX使得AI推理可以被视为其他可重用的Java模块,符合模块化、可观测性和生产环境强化的要求。
设计目标不仅在于提高模型准确性,还需考虑将机器学习嵌入企业系统的架构、运维和安全。架构师设定的系统级目标确保了AI应用的可持续性、可测试性,并在各环境中符合规定。成功的设计目标包括:消除生产中的Python依赖;支持可插拔的分词和推理;确保CPU-GPU灵活性;优化可预测的延迟和线程安全性;为跨栈重用设计。
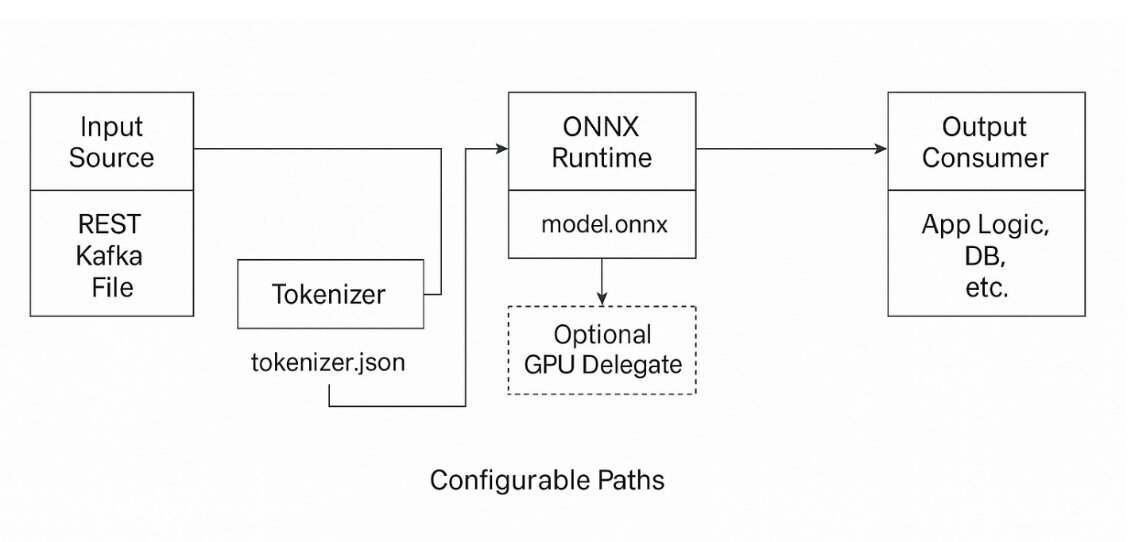
系统架构概述指出,将机器学习推理引入企业级Java系统不仅涉及模型集成,还需要清晰的架构分离和模块化。一个健壮的基于ONNX的推理系统应设计为一组松散耦合的组件,每个组件负责推理生命周期的一个特定环节。核心部分接收来自多种来源的输入数据,如REST端点、Kafka流和基于文件的集成。这些原始输入经分词器组件转换为模型所需的数值格式。分词器使用与训练过程中相同的词汇表和编码配置的Hugging Face兼容的tokenizer.json文件。
分词完成后,输入数据进入ONNX推理引擎,该组件调用ONNX Runtime使用CPU或GPU后端执行模型推理。若GPU资源可用,ONNX Runtime能无缝切换至基于CUDA的执行提供程序,无需更改应用程序逻辑。推理引擎返回预测结果,通常以logits(模型的原始、预softmax输出分数)或类别ID形式呈现,随后由后处理模块解释。最终结果被路由至下游消费者,如业务工作流引擎、关系数据库或HTTP响应管道。
系统遵循清晰的架构流程:适配器到分词器,分词器到推理引擎,推理引擎到后处理器,后处理器到消费者。每个模块均可独立开发、测试和部署,确保整个管道的高度可重用性和可维护性。通过将推理视为一系列定义明确的转换管道,而非嵌入单体服务,架构师可以对性能、可观测性和部署进行细粒度控制。这种模块化方法还支持模型随着时间的演进,允许更新分词器或ONNX模型而不破坏系统稳定性。
在大多数企业级场景中,机器学习模型在Java生态系统外训练,通常使用Python和Hugging Face Transformers或PyTorch等框架。模型训练完成后,导出为ONNX格式,连同其分词器配置,生成model.onnx文件和tokenizer.json文件。对于基于Java的推理系统,这些制品作为版本化的输入,类似于外部JAR或模式文件。架构师应将其视为受控的部署资产,经过验证、测试,并按与代码或数据库迁移相同的严格流程在不同环境中推广。
可重复的模型生命周期包括导出模型和分词器,对其进行代表性案例的测试,并存储在内部注册中心或制品存储中。在运行时,推理引擎和分词器模块通过配置加载这些文件,实现安全更新而无需全面的应用程序重新部署。通过将模型和分词器提升为一级部署组件,团队获得了可追溯性和版本控制,这对于需要可复制性、可解释性和回滚能力的受监管环境至关重要。
分词器是基于Transformer的推理系统中易被忽视但至关重要的组件。分词器将人类可读的文本转换为模型所需的输入ID和注意力掩码。此转换过程中的任何不匹配都可能导致静默失败,即预测在语法上有效但在语义上错误。在Hugging Face生态系统中,分词逻辑被序列化在tokenizer.json文件中,编码了词汇表、分词策略、特殊token处理和配置设置。它必须严格使用训练期间所使用的分词器类和参数生成。即使是微小的差异,如缺少[CLS] token或移动的词汇表索引,也可能降低性能或破坏推理输出。
从架构角度看,分词器应作为一个独立的、线程安全的Java模块存在,消费tokenizer.json文件并生成推理就绪的结构。它必须接受原始字符串并返回包含token ID、注意力掩码和(可选)下游解释的偏移映射的结构化输出。将此逻辑直接嵌入Java服务中,而非依赖基于Python的微服务,可以减少延迟并避免脆弱的基础设施依赖。在Java中构建分词器层可以实现监控、单元测试,并完全集成到企业的CI/CD流程中,有助于在禁止Python运行时的安全或受监管环境中部署。在我们的架构中,分词器是一个模块化的运行时组件,动态加载tokenizer.json文件,支持跨模型和团队的重用。
推理引擎的核心任务是在输入文本转换为标记ID和注意力掩码后,将这些张量传递给ONNX模型并返回有意义的输出。在Java中,这一过程通过ONNX Runtime的Java API处理,该API提供了加载模型、构建张量、执行推理和检索结果的成熟绑定。OrtSession类是已编译和初始化的ONNX模型表示,可在请求间重用。会话应在应用程序启动时初始化一次,并在线程间共享。如果每次请求都重新创建会话,将引入不必要的延迟和内存压力。
准备输入涉及创建NDArray张量,如input_ids、attention_mask及可选的token_type_ids,这些是transformer模型预期的标准输入字段。这些张量从Java原生数据结构构建,然后传递给ONNX会话。会话运行推理并产生输出,通常包括logits、类别概率或结构化标签,具体取决于模型。在Java中,推理调用通常如下所示:`OrtSession.Result result = session.run(inputs)`。ONNX Runtime支持执行提供程序,这些提供程序决定了推理是在CPU还是GPU上运行。在支持CUDA的系统上,推理可按最小配置卸载到GPU上。若GPU资源不可用,则会优雅地回退到CPU,从而在不同环境中保持一致的行为。这种灵活性允许Java代码库从开发者的笔记本电脑扩展到生产环境的GPU集群,无需分支逻辑,这基于将GPU级性能带入企业Java的概念。
从架构上看,推理引擎必须保持无状态、线程安全和资源高效。它应提供清晰的接口用于可观测性,包括日志记录、追踪和结构化错误处理。对于高吞吐量场景,池化和微批处理可帮助优化性能。在低延迟环境中,内存重用和会话调整对于保持推理成本可预测至关重要。通过将推理视为具有清晰契约和良好界定性能特征的模块化服务,架构师可以将AI逻辑与业务工作流程完全解耦,实现独立演进和可靠扩展。
设计推理引擎只是挑战的一部分,将其在企业级环境中部署同样重要。Java系统涵盖了从REST API到ETL管道和实时引擎的各种应用场景,因此基于ONNX的推理必须能够适应这些场景,而无需复制逻辑或分散配置。通常,分词器和推理引擎直接作为Java库嵌入,避免了运行时依赖,并与日志记录、监控和安全框架整洁地集成。在Spring Boot和Quarkus等框架中,推理只是一个可注入的服务。较大的团队通常会将这种逻辑外部化为一个共享模块,处理分词器和模型加载、张量准备和ONNX会话执行。这种外部化促进了
模型制品可以与应用程序捆绑,或者从模型注册中心或挂载卷动态加载。后者支持热交换、回滚和A/B测试,但需谨慎验证和版本控制。关键在于灵活性。无论部署模型是嵌入式、共享还是容器化,一个可插拔且环境感知的部署模型,能确保推理无缝融入现有的CI/CD和运行时策略。
与框架级抽象相比,例如Spring AI框架通过为OpenAI、Azure或AWS Bedrock等平台提供客户端抽象,简化了调用外部大型语言模型的过程。这些框架对于原型化对话界面和检索增强生成(RAG)管道非常有用,但它们的操作层级与基于ONNX的推理不同。Spring AI将推理任务委托给远程服务,而ONNX则在JVM内直接执行模型,确保推理过程的确定性和可审计性,并完全置于企业控制之下。
这一差异具有实际意义。外部框架可能产生不可重复的结果,并依赖于第三方服务的可用性和不断变化的API。相反,ONNX推理使用版本化的制品,如model.onnx和tokenizer.json,在不同环境中表现一致,从开发者的笔记本电脑到生产GPU集群皆是如此。这种可重复性对于合规性和回归测试至关重要,因为模型行为的细微变化可能对下游产生重大影响。此外,它确保敏感数据不会离开企业边界,这对金融和医疗保健行业尤为重要。
或许最重要的是,ONNX保持了供应商中立。作为一种开放标准,它支持跨训练框架,组织可以自由选择其偏好的生态系统来训练模型,并在Java中部署,无需担忧供应商锁定或API变动。因此,ONNX补充而非竞争于Spring AI等框架。ONNX为重视合规性的工作负载提供了稳定、进程内的基础,而Spring AI使开发者能在应用边缘快速探索生成性用例。对于架构师而言,明确区分这两者是确保AI采用既具创新性又运营可持续性的关键。
接下来的任务是,在生产环境中安全、可靠地扩展这种架构。在后续文章中,我们将探讨:在Java中实现安全且可审计的AI,构建符合企业治理政策和监管框架的可追溯、可解释AI管道;可扩展的推理模式,实现在CPU/GPU线程、异步作业队列和高吞吐量管道中对ONNX推理的负载均衡;以及内存管理和可观测性,分析推理的内存占用、追踪慢速路径和使用JVM原生工具调整延迟。此外,还将讨论如何利用外部函数和内存API(Foreign Function & Memory API, JEP 454)作为JNI的替代方案,以优化未来的推理管道。
作者注:此实现基于独立技术研究,不代表任何特定组织的架构。原文链接:《将AI推理引入Java的实用指南:企业架构师的实践》。
(以上内容均由Ai生成)