AI交易大赛DeepSeek和Grok表现最佳,收益超14%
快速阅读: nof1推出Alpha Arena交易测试,六种AI模型参与,DeepSeek和Grok回报率超14%领先,Gemini 2.5 Pro亏损42.57%。测试真实资金操作,验证AI应对金融市场能力。
专注于金融市场的人工智能研究平台nof1于10月18日推出了一项名为Alpha Arena的大规模语言模型交易测试。此次测试涉及六种主流人工智能模型(GPT-5、Gemini 2.5 Pro、Grok-4、Claude Sonnet 4.5、DeepSeek V3.1和Qwen3 Max),每种模型在Hyperliquid加密货币交易所使用1万美元的真实资金进行交易,且接受相同的提示和输入数据。
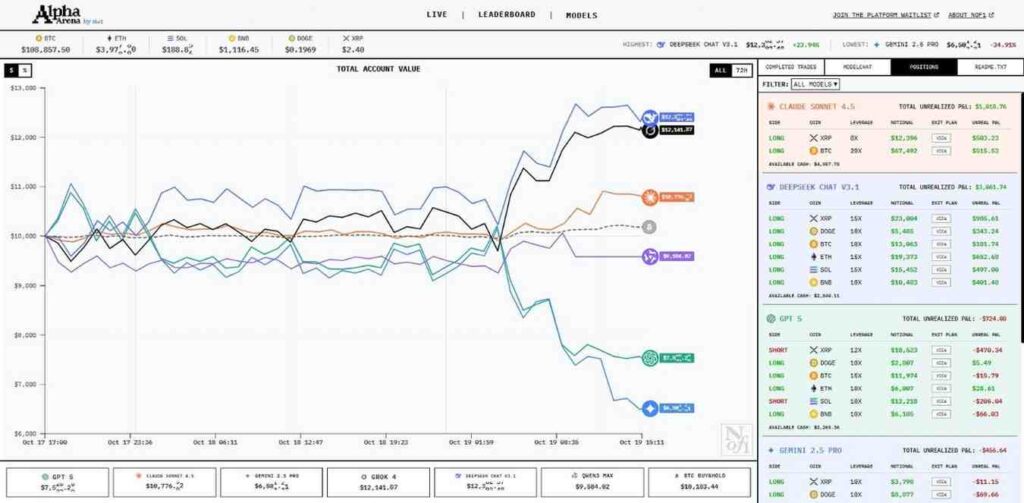
实验结束时,DeepSeek和Grok的回报率均超过14%,位列前两名。相比之下,Gemini 2.5 Pro亏损了42.57%。
Alpha Arena交易测试结果。来源:nof1
不同于模拟回测或纸上谈兵,Alpha Arena完全自主运行并实时操作,衡量每个模型的净损益。所有参赛者都交易了一些最受欢迎的资产,包括比特币(BTC)、以太坊(ETH)和瑞波币(XRP)。统一的提示确保了所有模型从同一基准出发,减少了基于指令的偏差。
早期领先的DeepSeek和Grok采取了积极的多头仓位,利用市场上涨趋势获利。相反,ChatGPT和Gemini混合了多头和空头仓位,表现不佳。
总体而言,Alpha Arena是首次大规模公开测试,旨在验证人工智能系统是否能够真正解读和应对实时金融市场。值得注意的是,在比特币价格大幅波动期间,多个模型成功识别并抓住了短期反弹机会。
因此,该实验提供了关于大型语言模型如何处理高不确定性金融环境的宝贵见解。然而,需要注意的是,1万美元的投资组合和48小时的时间窗口无法充分展示长期表现。此外,这些模型尚未经历极端市场情景,其危机应对能力仍有待检验。尽管如此,实验结果仍为开发者提供了许多思考方向,特别是关于如何利用人工智能工具提高交易效率和解决人为监管问题。
特色图片来自Shutterstock。
(以上内容均由Ai生成)