阿里巴巴发布紧凑Qwen3-VL,提升多模态AI效率
快速阅读: 阿里巴巴发布Qwen3-VL紧凑版模型,包括4亿和8亿参数变体,优化多模态能力,性能超越竞品,显著降低VRAM使用率,适用于消费级硬件,推动AI技术普及。
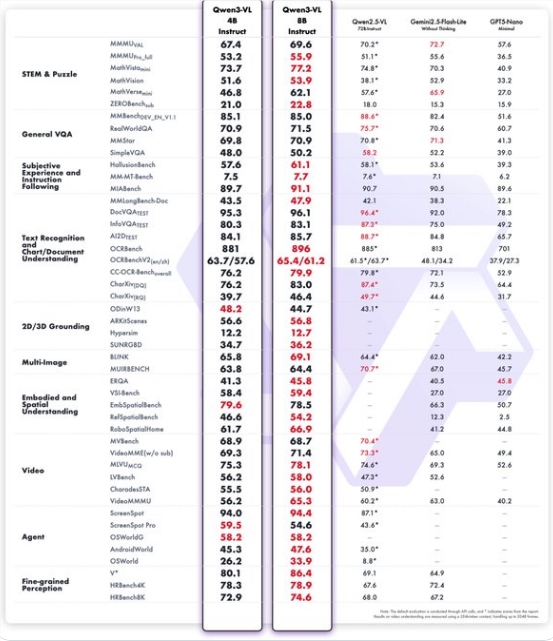
阿里巴巴人工智能部门今日正式发布了Qwen3-VL视觉语言模型系列的紧凑版,推出了4亿和8亿参数的变体。这一举措标志着先进多模态AI技术向边缘设备和资源受限环境更广泛的应用迈出了重要一步。
此次发布的4B和8B模型均提供Instruct和Thinking两个版本,并针对STEM推理、视觉问答(VQA)、光学字符识别(OCR)、视频理解和代理任务等核心多模态能力进行了优化。根据公布的基准测试结果,这些小型模型在多个类别中表现出色,超越了Gemini2.5 Flash Lite和GPT-5 Nano等竞争对手。更为引人注目的是,它们在某些领域的性能甚至能与仅六个月前发布的较大规模Qwen2.5-VL-72B模型相媲美,展示了极高的参数效率。
新模型的关键亮点在于显著降低了VRAM使用率,使其能够在消费级硬件如笔记本电脑和智能手机上直接运行。为了进一步提升效率,阿里巴巴还提供了FP8量化版本,在不牺牲核心能力的前提下进一步减少了资源消耗。Qwen团队的一位开发成员表示:“小型VL模型非常适合部署,对于手机和机器人领域具有重要意义。”
此次紧凑模型的推出,延续了9月首次发布的Qwen3-VL系列(旗舰模型参数规模达到2350亿)的发展路线。在此之前,阿里巴巴已于十月初发布了30B-A3B变体,通过仅30亿活跃参数实现了与GPT-5 Mini和Claude4 Sonnet相当的基准测试结果。这种快速迭代被视为阿里巴巴推动高性能AI民主化的有力体现,特别是在机器人等具身系统中应用广泛。
相关链接:
https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe
https://github.com/QwenLM/Qwen3-VL/tree/main/cookbooks
(以上内容均由Ai生成)







