蚂蚁发布万亿参数思考模型Ring-1T,开源刷新SOTA
快速阅读: 蚂蚁集团推出万亿参数思考模型Ring-1T,开源模型权重及训练配方,强化自然语言推理与通用能力,解决IMO难题,表现优异,采用“棒冰”算法优化训练稳定性。
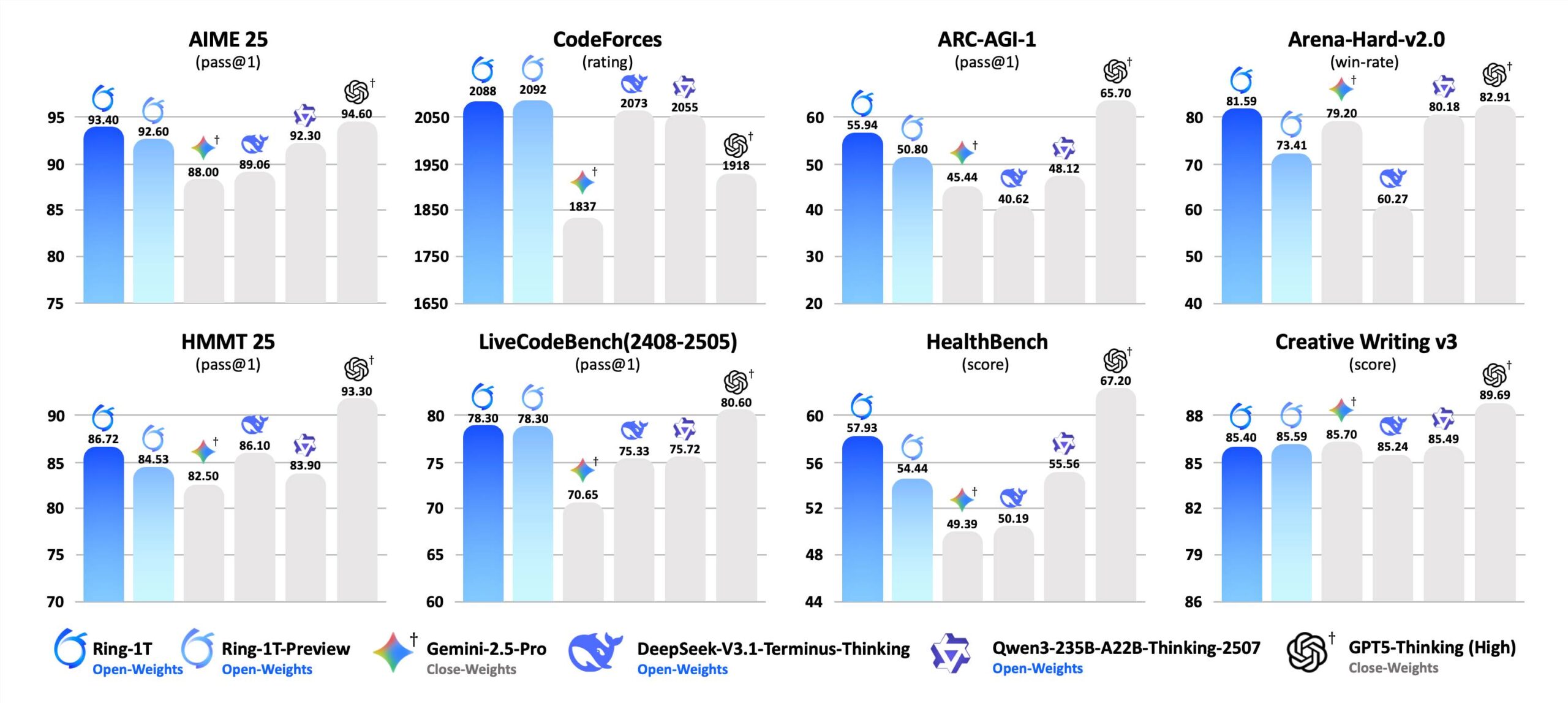
10月14日凌晨,蚂蚁集团正式推出了万亿参数思考模型Ring-1T,并全面开源了模型权重及训练配方。Ring-1T在9月30日开源的预览版Ring-1T-preview基础上,持续扩展大规模可验证奖励强化学习(RLVR)训练,进一步增强了万亿基座的自然语言推理能力,并通过RLHF训练提升了模型的通用能力,在各项任务榜单上表现出色,更加均衡。
为了进一步激发Ring-1T在数学等复杂推理方面的能力,百灵团队此次挑战了难度更高的IMO2025(国际数学奥林匹克)赛题,将Ring-1T接入多智能体框架AWorld,使用纯自然语言推理进行解题。实验结果显示,Ring-1T仅一次就解决了第1、3、4、5题,达到了IMO银牌水平,成为首个能够获得IMO国际数学奥林匹克奖项的开源系统。在第三次尝试IMO时,Ring-1T对第2题的几何证明给出了接近满分的证明过程,在其他顶级大模型几乎全军覆没的第6题中,Ring-1T的答案收敛到了与Gemini2.5Pro相同的“4048”(正确答案为2112)。作为一款思考模型,Ring-1T在“人类偏好对齐”测试Arena-Hard V2中,以81.59%的成功率位居开源模型榜首,接近GPT-5-Thinking(High)的82.91%的成绩。在面向严谨领域的医疗问答HealthBench测评中,Ring-1T同样取得了最高分,成为开源领域的最佳。
万亿参数思考模型训练的最大难题在于训推精度差异,即由于实现细节的不同导致训练阶段与推理阶段的精度不一致,从而引发训练崩溃。在Ring-1T模型中,蚂蚁集团采用了自主研发的“棒冰(icepop)”算法,通过带掩码的双向截断技术将训练-推理分布差异冻结在低水平,确保长序列、长周期训练的稳定性。此外,针对万亿参数模型的强化学习训练,蚂蚁集团还自主研发了高性能强化学习系统ASystem(其中包含已开源的高性能强化学习框架AReaL),专门针对万亿参数模型的显存管理和训推权重交换问题进行了优化,实现了单机显存碎片的秒级回收和权重的零冗余交换,使得大规模RL训练能够稳定运行。
本次发布的Ring-1T模型继续采用Ling2.0架构的1T基础模型进行后训练,Ling2.0采用了高度稀疏的MoE架构、1/32的专家激活比、FP8混合精度、MTP等多项技术,实现了高效的训练与推理。在后训练阶段,蚂蚁百灵团队通过LongCoT-SFT + RLVR + RLHF多阶段训练,显著提高了模型的复杂推理能力和指令跟随、创意写作等通用能力。
据百灵团队透露,Ring-1T模型是其在万亿思考模型上的首次尝试,未来将在后续版本中继续优化模型性能。目前,用户可以通过HuggingFace、魔搭社区下载模型,并通过蚂蚁百宝箱等平台在线体验。
据了解,截至目前,蚂蚁百灵大模型已发布了18款模型,形成了从160亿总参数到1万亿总参数的大语言模型产品矩阵,其中包括两款万亿参数模型——万亿参数通用大语言模型Ling-1T和万亿参数思考模型Ring-1T。随着这两款万亿参数模型的发布,百灵大模型正式进入了2.0阶段。
(以上内容均由Ai生成)







