蚂蚁集团发布dInfer,加速扩散语言模型推理10倍
快速阅读: 蚂蚁集团开源dInfer框架,实现扩散语言模型推理速度大幅提升,比英伟达Fast-dLLM快10.7倍,有望推动AI技术广泛应用。
近日,蚂蚁集团正式开源了业内首个高性能扩散语言模型推理框架——dInfer。这一框架的推出,不仅标志着扩散语言模型在推理速度上的重大突破,还表明该技术向实际应用迈出了重要一步。
在最新的基准测试中,dInfer的推理速度比英伟达的Fast-dLLM框架提高了10.7倍。在代码生成任务HumanEval中,dInfer实现了每秒1011个Tokens的速度,首次在开源社区中显著超越了传统自回归模型的推理速度。这一进展令人们对扩散语言模型的未来充满期待,认为它可能成为通往通用人工智能(AGI)的关键技术路径。
扩散语言模型的独特之处在于它将文本生成视为一个“从随机噪声中逐步恢复完整序列”的去噪过程,具有高度并行、全局视野和结构灵活的特点。尽管理论上拥有巨大的潜力,但在实际推理过程中,扩散语言模型受到高计算成本、KV缓存失效和并行解码等挑战的影响,导致其推理速度难以充分发挥。
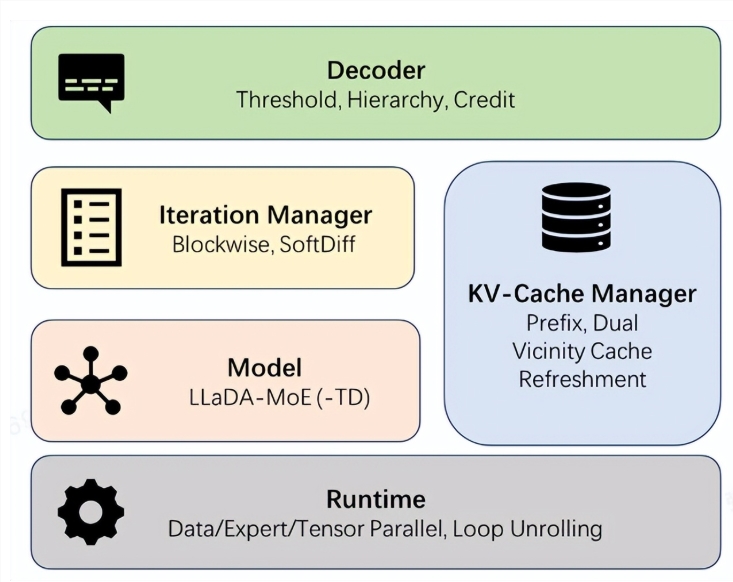
针对这些问题,dInfer专门设计了四大核心模块:模型接入、KV缓存管理器、扩散迭代管理器和解码策略。这种模块化的设计,如同乐高积木一般,允许开发者灵活组合和优化各部分,同时在统一的平台上进行标准化评估。
在配置有8块NVIDIA H800 GPU的节点上,dInfer表现出色。与Fast-dLLM相比,在效果相当的情况下,dInfer的平均推理速度达到681个Tokens/秒,而Fast-dLLM仅为63.6个Tokens/秒。此外,与业界领先的推理服务框架vLLM上运行的自回归模型Qwen2.5-3B相比,dInfer的速度提升了2.5倍。
蚂蚁集团表示,dInfer的推出是连接前沿研究与产业应用的重要一步,期待全球开发者和研究者共同探索扩散语言模型的潜力,构建更为高效和开放的AI生态。
(以上内容均由Ai生成)







