DeepSeek V3.1更新,优化中英文混杂和智能体稳定性
快速阅读: DeepSeek-V3.1更新至Terminus版本,优化语言一致性和Agent性能,解决中英文混杂问题,提升文本生成质量,标志着国产大模型向工程可靠性转变。
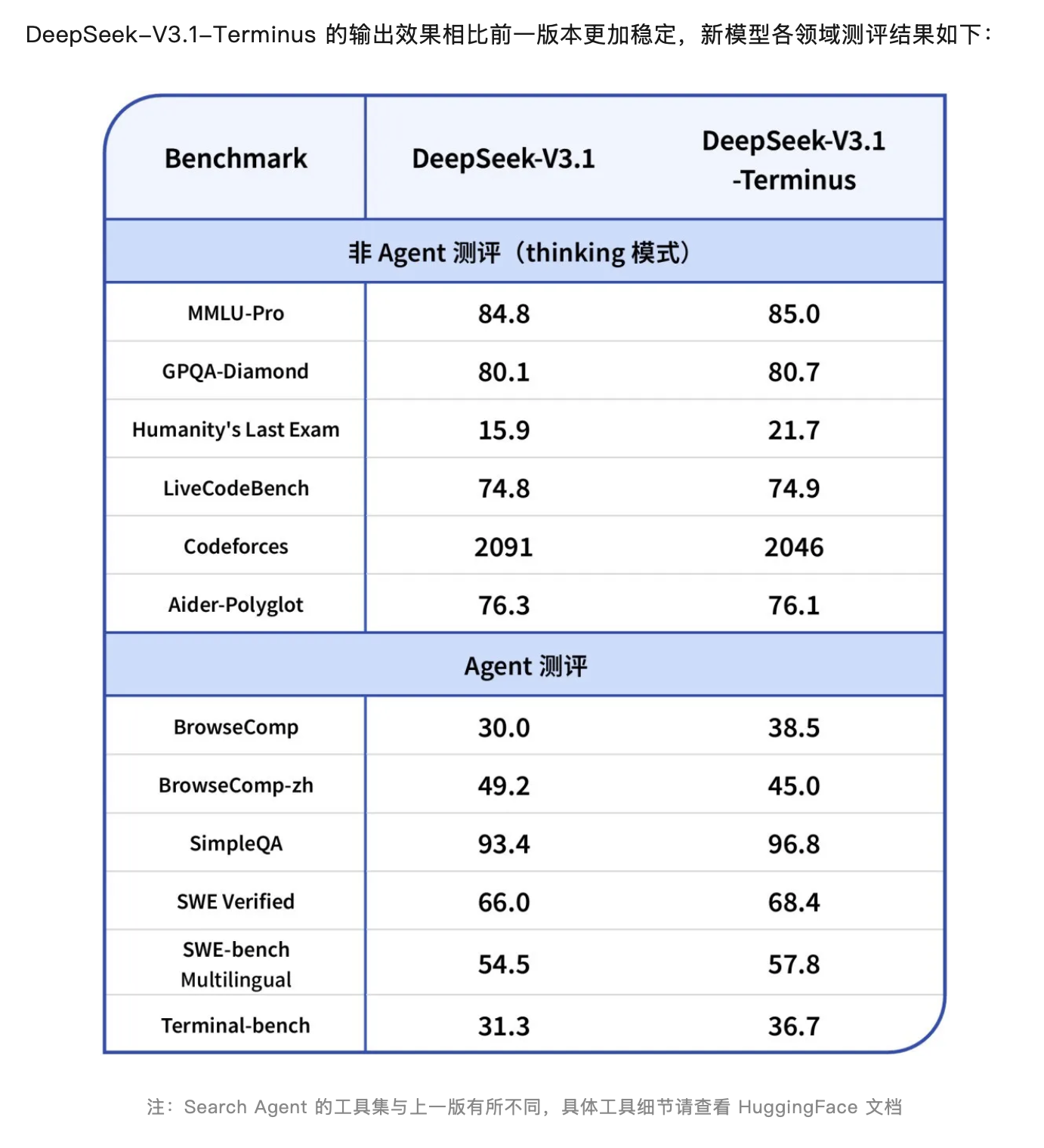
DeepSeek-V3.1已更新至DeepSeek-V3.1-Terminus版本。9月22日晚,DeepSeek介绍,此次更新在保留原有功能的同时,针对用户反馈的问题进行了多项改进,主要包括:语言一致性方面,减少了中英文混杂及偶发异常字符等问题。此外,还进一步优化了Code Agent与Search Agent的表现,使得DeepSeek-V3.1-Terminus的输出更为稳定。
目前,官方App、网页端、小程序及DeepSeek API均已同步更新至DeepSeek-V3.1-Terminus。值得注意的是,这款大模型命名为Terminus,意为“终极版”,暗示这可能是V3.1系列的最终更新。外界正关注下一次重大版本更新是否会是V4或R2。
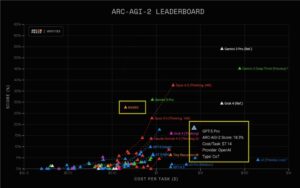
在公开的基准测试中,V3.1-Terminus整体表现优于V3.1,尽管某些指标略有下降,但在“人类最后考试”基准上的得分显著提高,从15.9升至21.7。根据官网数据,这一成绩仅次于Grok 4(25.4)和GPT-5(25.3),并略高于Gemini 2.5 Pro(21.6)。
尤其值得一提的是,DeepSeek在解决中英文混杂问题方面的改进受到了用户的广泛好评。澎湃新闻记者在社交媒体上观察到,许多用户对此表示赞赏:“长时间思考时确实会出现中英文混杂的问题,现在这个问题得到了很好的解决。”
资深AI投资人郭涛在接受澎湃新闻采访时分析,DeepSeek-V3.1-Terminus版本的更新重点在于工程化落地与场景适应,主要突破表现在两个方面:一是通过语义层降噪技术显著提升了语言一致性,减少了中英文混杂和异常字符等干扰,提高了文本生成的质量;二是深度重构了Agent执行框架,优化了Code Agent的语法解析精度和Search Agent的信息检索召回率,增强了智能体的输出稳定性。
此次全渠道同步升级,展示了国产大模型从算法创新向工程可靠性的关键转变,标志着国产模型在处理复杂任务和多模态协同等工业应用方面迈出了重要一步,为未来在垂直领域的深入应用奠定了坚实的基础。
作为国产大模型的标杆,DeepSeek的每一次动态都备受瞩目。9月18日,梁文锋携DeepSeek-R1研究成果登上了国际顶级期刊《自然》封面。
今年1月,深度求索(DeepSeek)在预印本平台arXiv上发布了论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》,论文作者名单中包括创始人梁文锋。《自然》杂志评论,DeepSeek-R1的进步在于,如果大模型能够规划解决问题的步骤,就能更有效地解决问题,这种“推理”能力类似于人类解决复杂问题的方式,对AI来说是一个巨大挑战,通常需要人工干预以添加标签和注释。
DeepSeek的研究团队揭示了他们在极少量人工输入的情况下如何训练模型进行推理。DeepSeek-R1采用了强化学习方法,当模型正确解答数学问题时会得到奖励,反之则会受到惩罚。
针对“蒸馏”技术的质疑,DeepSeek团队首次作出回应,论文中明确表示,DeepSeek-V3-Base的训练数据仅来源于普通网页和电子书,未包含任何合成数据。虽然部分网页可能含有由OpenAI模型生成的内容,但这并非团队有意为之,所有预训练数据均为自然获取。预训练数据集中包含大量与数学和代码相关的内容,这表明DeepSeek-V3-Base接触到了丰富的推理路径数据。
1月20日,中国AI初创公司深度求索推出了开源大模型DeepSeek-R1,该模型在数学、编程和自然语言推理等任务上的表现可与OpenAI的正式版模型相媲美,并采用MIT许可协议,支持免费商用、修改和二次开发。春节后,国内多家行业领先企业宣布接入DeepSeek。
随着AI大模型行业的快速发展,DeepSeek已推出多个新版本,但备受期待的R2仍未面世。8月21日,DeepSeek正式发布了DeepSeek-V3.1,标志着其向Agent(智能体)时代迈出了第一步。
(以上内容均由Ai生成)