LeCun提出新模型LLM-JEPA,用CV技术重塑语言模型性能
快速阅读: Yann LeCun 提出 JEPA 架构,革新 LLM 训练方法,通过预测抽象表征空间中缺失特征,提升模型性能与鲁棒性,尤其在防止过拟合方面表现优异,为未来语言模型发展指明方向。
在当今的人工智能领域,Yann LeCun 提出的 JEPA(联合嵌入预测架构)正在重新定义大型语言模型(LLM)的训练方式。作为诺贝尔奖得主,LeCun 并未批评现有的 LLM,而是亲自动手进行改进。传统的 LLM 训练方法主要依赖于输入空间中的重构与生成,例如预测下一个单词,这种方法在视觉领域已显示出局限性。
LeCun 及其团队认为,可以借鉴计算机视觉(CV)领域的先进技术来提高语言模型的表现。JEPA 的核心思想是在抽象表征空间中预测缺失的特征,从而高效地学习世界知识。Meta AI 团队已在图像和视频处理上成功应用了 JEPA,现在他们希望将这一理念扩展到语言模型领域。
为填补这一空白,研究人员 Hai Huang、Yann LeCun 和 Randall Balestriero 共同提出了 LLM-JEPA。这一新模型首次成功将 JEPA 的自监督学习架构应用于 LLM,将文本和代码视为同一概念的不同视角。通过结合 JEPA 在嵌入空间学习的优势,LLM-JEPA 不仅保留了 LLM 强大的生成能力,还在性能和鲁棒性上取得了显著提升。
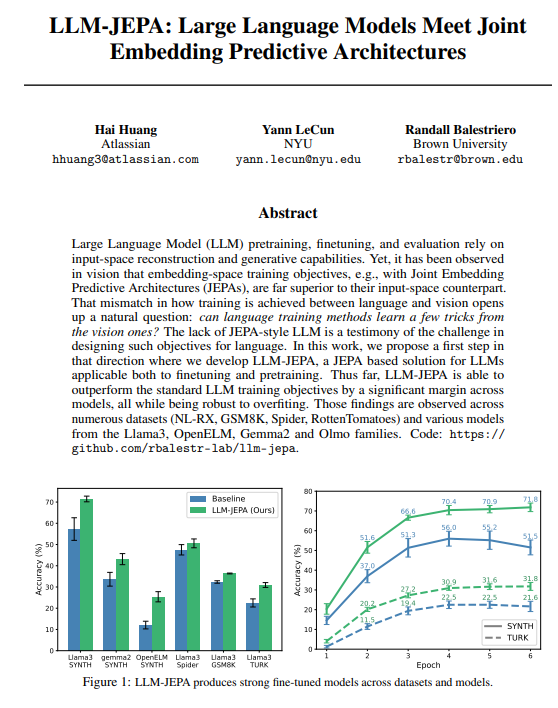
实验表明,LLM-JEPA 在多个主流模型(如 Llama3、OpenELM、Gemma2 等)和多样化数据集(如 GSM8K、Spider 等)上的表现优于传统 LLM 训练目标,尤其是在防止过拟合方面显示出强大的鲁棒性,为语言模型的未来发展指明了新的方向。
尽管当前研究主要集中在微调阶段,但初步的预训练结果已显示出巨大潜力。团队计划在未来的工作中进一步探索 LLM-JEPA 在预训练过程中的应用,期待为语言模型的性能提升注入新的动力。
(以上内容均由Ai生成)







