谷歌发布TimesFM-2.5,参数减半上下文延长至16384点
快速阅读: 谷歌发布TimesFM-2.5,参数减至2亿,上下文长度增至16,384数据点,支持本地概率预测,GIFT-Eval评估中表现优异。
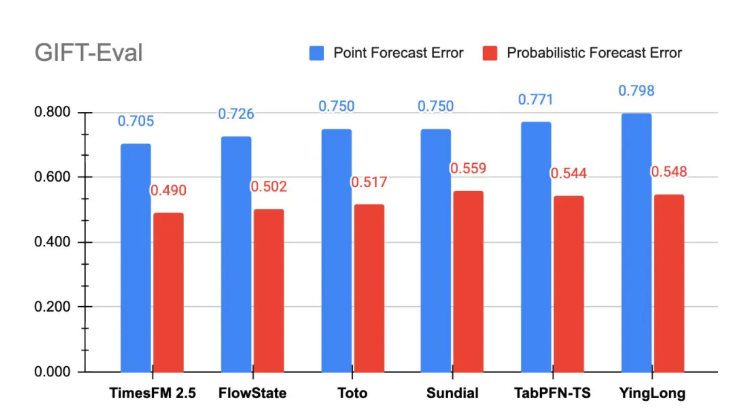
谷歌研究团队近日发布了 TimesFM-2.5,这是一款拥有2亿参数、采用单一解码器结构的时间序列基础模型。相比前一版本,TimesFM-2.5在参数数量上大幅减少,从5亿降至2亿。同时,新模型的上下文长度显著提升,达到16,384个数据点。此外,TimesFM-2.5支持本地概率预测,已在Hugging Face平台上线,并在GIFT-Eval的准确性评估中名列前茅。
时间序列预测是对随时间变化的数据点进行分析,以识别模式并预测未来值的技术。它在多个行业中有重要作用,如零售商品需求预测、天气和降水趋势监测,以及供应链和能源网络的优化。通过捕捉时间依赖性和季节性变化,时间序列预测在动态环境中支持数据驱动的决策。
与之前的TimesFM-2.0相比,TimesFM-2.5的主要改进包括:首先,参数数量显著减少;其次,最大上下文长度的提升使其能更好地捕捉多季节性结构和低频成分,简化了预处理步骤;最后,新模型引入了量化预测的可选功能,支持最多1,000个预测点。
上下文长度的增加为何重要?16,384个历史数据点的支持使模型能在单次前向传递中更全面地捕捉数据的长期趋势。对于受历史影响显著的领域,如能源负载和零售需求预测,这一点尤为重要。
TimesFM的核心理念是利用单一解码器基础模型进行预测,这一理论首次在2024年的ICML会议上被提出。GIFT-Eval(由Salesforce发起)旨在为不同领域的评估标准化提供支持,并在Hugging Face上设立了公共排行榜,方便模型性能的对比。
TimesFM-2.5标志着时间序列预测基础模型从概念走向实际应用,展现了在保持较小参数量的同时,提高模型准确性和效率的可能性。该模型已在Hugging Face上线,并将进一步与BigQuery和Model Garden集成,推动零样本时间序列预测在实际应用中的广泛采用。
链接:https://huggingface.co/google/timesfm-2.5-200m-pytorch
要点:
– 参数减少至2亿,同时提高了准确性。
– 支持16,384个数据点的输入长度,实现更深入的历史数据预测。
– 在GIFT-Eval评估中,TimesFM-2.5在点预测和概率预测方面均位列第一。
(以上内容均由Ai生成)







