Meta发布轻量级模型MobileLLM-R1,性能显著提升
快速阅读: Meta AI 发布 MobileLLM-R1 系列轻量级模型,参数规模 140M 至 950M,专注高效数学、编码和科学推理,性能优异,训练效率高,使用 FAIR NC 许可,适合边缘设备。
近日,Meta AI 发布了 MobileLLM-R1,这是一系列轻量级边缘推理模型,现已在 Hugging Face 平台上发布。该系列模型的参数规模从 140M 至 950M 不等,专注于高效的数学、编码和科学推理,在不足 10 亿参数的情况下展现出优秀的性能。
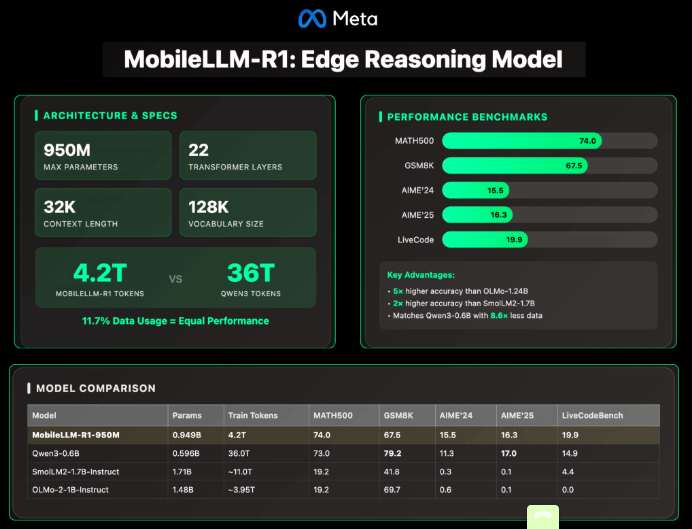
MobileLLM-R1 的最大型号是 MobileLLM-R1-950M,采用了 22 层 Transformer 架构、24 个注意力头及 6 个分组 KV 头。模型的嵌入维度为 1536,隐藏层维度为 6144。此外,通过引入分组查询注意力(GQA)以减少计算和内存需求,块级权重共享技术减少了参数数量而不会显著增加延迟,SwiGLU 激活函数增强了小模型的表示能力。该模型支持 4K 的上下文长度和 32K 的后训练模型。
在训练效率方面,MobileLLM-R1 表现出色。它在大约 4.2 万亿个 token 上进行了训练,相比之下,Qwen3 的 0.6B 模型在 36 万亿个 token 上训练,MobileLLM-R1 仅用了前者约 11.7% 的数据就达到了或超过了 Qwen3 的准确率。同时,该模型还在数学、编码和推理数据集上进行了监督微调,从而降低了训练成本和资源需求。
在多个基准测试中,MobileLLM-R1-950M 展现了卓越的性能:在 MATH500 数据集上,其准确率是 OLMo-1.24B 的约 5 倍,比 SmolLM2-1.7B 高出约 2 倍。在 GSM8K、AIME 和 LiveCodeBench 等推理和编码任务中,MobileLLM-R1 与 Qwen3-0.6B 相匹敌甚至超越,尽管使用的 token 数量远少于后者。
然而,MobileLLM-R1 的专精领域也带来了一些局限性。尽管在数学、编码和结构化推理方面表现出色,但在一般对话、常识推理和创意任务上,其表现不如大型模型。此外,该模型在生产环境中的使用受 FAIR NC(非商业)许可限制,较长的上下文(32K)增加了推理时的 KV 缓存和内存需求。
总体而言,Meta 的 MobileLLM-R1 展示了一种趋势,即向更小、更专业的模型发展,这些模型能在没有大规模训练预算的情况下提供具有竞争力的推理能力。特别是在数学、编码和科学应用领域,MobileLLM-R1 表现尤为突出,为边缘设备上的大规模语言模型部署设定了新标准。
(以上内容均由Ai生成)







