阿里巴巴发布FunAudio-ASR,显著提升嘈杂环境语音识别准确率
发布时间:2025年9月16日
来源:szf
快速阅读: 阿里巴巴通义实验室发布FunAudio-ASR,创新“Context模块”大幅提升高噪声环境下的语音识别准确率,幻觉率降至10.7%。该模型已应用于钉钉等产品,促进AI技术发展。
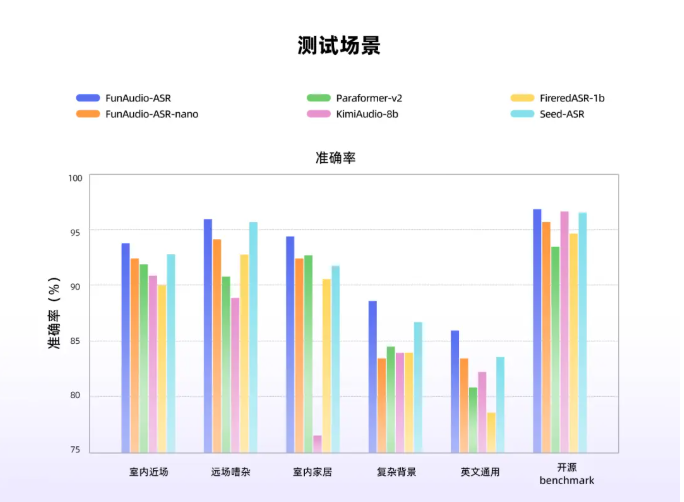
近日,阿里巴巴通义实验室正式发布了最新的端到端语音识别大模型——FunAudio-ASR。该模型的最大亮点在于其创新的“Context模块”,显著提升了高噪声环境下语音识别的准确率,将幻觉率从78.5%大幅降至10.7%,降幅接近70%。这项技术突破不仅为语音识别行业设立了新标准,尤其在会议、公共场所等嘈杂环境中表现出色。
在训练过程中,FunAudio-ASR模型采用了数千万小时的音频数据,并融合了大语言模型的语义理解能力,使其在远场、嘈杂和多说话人等复杂条件下的性能超越了Seed-ASR、KimiAudio-8B等主流语音识别系统。通过这一技术的应用,用户可以享受更加清晰和准确的语音识别体验。
除了完整版外,阿里还推出了轻量级版本FunAudio-ASR-nano。该版本在保持高识别准确率的同时,降低了推理成本,适合资源需求较高的部署环境。无论是大型企业还是小型团队,都能找到适合自己需求的解决方案。
目前,FunAudio-ASR已在钉钉的“AI听记”功能、视频会议及DingTalk A1硬件中得到实际应用。此外,其API也已在阿里云百炼平台正式上线,便于开发者集成和使用。对企业用户来说,这意味他们可以通过这一先进技术提高会议效率,改善沟通效果。
FunAudio-ASR不仅为语音识别技术带来了新的突破,也为用户的实际应用提供了强有力的支持,促进了AI技术的普及和发展。
(以上内容均由Ai生成)







