「香蕉革命」首揭秘,谷歌疯狂工程师死磕文字渲染,竟意外炼出最强模型

快速阅读: 谷歌发布图像模型nano banana,融合多张图片生成新画面,理解地理与物理结构,将二维地图转为三维景观,具备“有记忆”的多轮创作能力,重塑AI图像生成边界。
谷歌发布了最新图像模型nano banana,该模型不仅能够融合多张图片拼接出全新画面,还能理解地理、建筑与物理结构,甚至将二维地图转化为三维景观。借助Gemini的世界知识与交错生成技术,nano banana实现了“有记忆”的多轮创作,带来极高的一致性与创造力,正重塑AI图像生成的边界,引发对未来“AI创意伙伴”的无限遐想。
谷歌发布的这款新图像模型迅速引爆社区,nano banana的热度堪比几个月前OpenAI的“吉卜力热”。与后者单一的生成风格不同,nano banana带来了更多颠覆性的玩法,谷歌可能也没有预料到网友们的创新力量如此强大。
用户最多可上传13张图片,让nano banana合并。模型的强大理解能力使其可以拼接物理世界的物体,甚至人物动作,如同分镜一般。此外,nano banana还能从二维地图中识别三维世界,理解等高线知识,绘制真实地理地貌,轻松处理工程绘图视角。
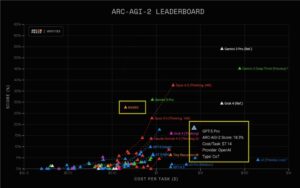
nano banana不仅可以生成高质量图像,还能修复老照片,补充破损、折痕,还原清晰画面。该模型在LMArena上线后迅速风靡,在最终盲测中,Gemini 2.5 Flash Image的成绩一骑绝尘,明显优于之前的图像模型。
谷歌DeepMind团队接受了采访,揭秘了nano banana背后的技术。模型可以访问多模态上下文,生成图像时能够查看之前的图像,并尝试生成不同的东西。交错生成技术将复杂的提示分解成多个步骤,逐一编辑,使模型不仅生成高质量图像,还能理解深层意图,提供更有创造性的结果,确保内容的真实性和准确性。
在谷歌内部,团队通过收集推特上的用户反馈不断改进模型。研究工程师Robert回忆称,2.0版本发布后,团队认真对待每一条反馈,尤其是关于文字渲染的问题。最终,这些努力使模型的能力大幅提升。
Gemini团队与Imagen团队的合作是模型成功的关键。Gemini团队赋予模型世界知识和指令遵循能力,Imagen团队则负责提升图像质量,确保每个编辑都达到最佳效果。未来,团队希望模型能成为比用户更聪明的创意伙伴,不仅能生成高质量图像,还能提供超出用户预期的结果。
(以上内容均由Ai生成)