贝壳商机平台实践NL2SQL实现指标查询
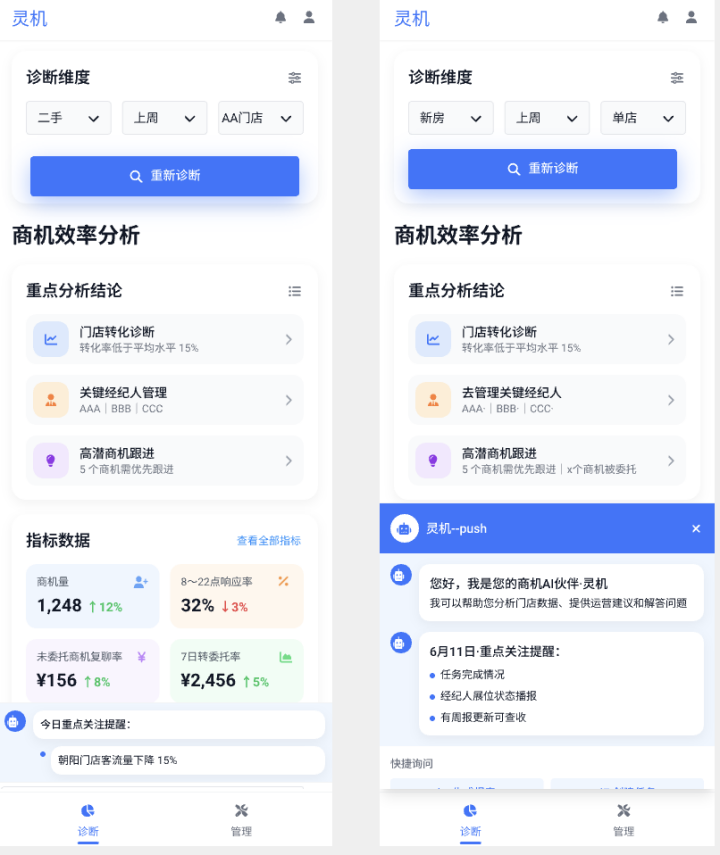
快速阅读: 门店商机管理助手为店东提供智能化管理工具,整合关键指标数据,结合客户沟通场景深度挖掘,实现多维度对比分析,精准定位业务薄弱环节,输出针对性建议,提升商机转化率,推动业绩增长。
门店商机管理助手专为店东设计,是一款智能化门店管理工具。该工具整合了门店旗下经纪人作业过程中的关键指标数据,并结合客户沟通场景进行深度数据挖掘。系统能够实现多维度对比分析,精准定位业务薄弱环节,并基于数据分析结果输出针对性建议和举措。店东可以根据这些建议和举措对经纪人进行有效管理,帮助经纪人优化作业流程、提升专业服务能力,最终实现商机转化率的显著提高,推动门店业绩增长,构建数据驱动的管理闭环。
门店商机管理助手采用“Chat 交互 + GUI 可视化”混合形态构建工具矩阵,既支持通过智能对话引擎(Chat)为店东提供实时业务指标咨询、数据解读及策略建议(如经纪人作业优化方案、客户沟通话术指导等),又依托图形用户界面(GUI)打造可视化数据看板,直观展示经纪人作业过程中的各项指标(如商机、转化、客户解读等)。这种“对话式交互 + 可视化分析”的双引擎模式,使店东能够在动态决策的灵活性与数据管理的精准性之间找到平衡,实现从“数据洞察”到“业务优化”的全流程效率提升。
在门店商机管理助手中,作业指标查询是核心能力之一。该功能依托商机指标平台构建的标准化数据底座,实现了从指标建模、指标加工到数据存储的标准流程。作为工具的数据根基,指标平台不仅提供指标数据,还提供指标字典和元数据定义。在此基础上,作业指标查询功能结合 Chat 智能交互引擎,系统可以自动响应自然语言查询指令(如“查询门店转带看率周环比”),并同步输出优化建议,形成“数据查询 – 智能分析 – 策略生成”的闭环能力,确保店东基于精准数据底座进行业务决策,夯实商机转化的过程管理根基。
在作业指标查询方面,NL2SQL(自然语言转 SQL)与 NL2DSL(自然语言转领域特定语言)是两种通用方案。NL2DSL 通过语义解析将自然语言查询转换为中间层领域特定语言(DSL),再由 DSL 映射生成目标 SQL 语句。例如,自然语言“查询 Q2 XX 门店带看量 Top10 的经纪人”转换为自定义 DSL 后,生成对应的 SQL 语句(select agent_id from table1 where shop=’XX’ and date>’XXXX’ order by show_count desc limit 10)。
具体实现流程包括定义 DSL 规则、开发 DSL 解析器及 SQL 映射器。NL2SQL 则直接将自然语言查询映射为数据库操作语言(DML,即原生 SQL 语句)。例如,自然语言“查询 2025 年 6 月商机量超过 100 的经纪人”直接生成 SQL 语句(SELECT 经纪人 ID FROM table WHERE 时间=’2025-06′ AND 商机量>100)。具体实现需要获取数据库表 schema 以生成 SQL 语句。
在构建自然语言查询能力的过程中,我们选择了基于 NL2SQL 技术方案,主要基于以下几方面的考虑:
1. 应用场景灵活,适配用户查询需求。自然语言查询具备良好的通用性和可扩展性。通过 NL2SQL,用户可以用一句话完成诸如“查询昨天北京 ccc 门店的带看量”、“近 7 日转化率趋势”等查询请求,避免了对字段、表结构、查询语法的深入理解。
2. 良好的基础设施支撑——商机指标平台。商机指标平台基于 Apache Doris 数据仓库构建,在表结构、指标体系和查询优化方面已形成规范化体系。平台特性天然适配 NL2SQL 技术的快速落地,具体体现在:
– 统一的数据存储引擎:平台底层基于 Doris 构建,无需适配多种异构数据源,SQL 接口统一,执行逻辑简洁。
– 清晰的指标字段映射:商机平台中的基础指标如“商机量”、“带看量”、“成交量”等在 Doris 表中均有明确字段表示,且已通过指标管理系统进行口径定义,无需额外引入 DSL 层来做字段转换和口径解释,降低了技术实现复杂度。
– 标准化的数据维度:包括时间字段(如 occur_date)、组织维度(如 agent_id, shop_id, area_id)等均已完成统一命名、格式化处理,使自然语言问题可快速对齐到字段层,无需复杂的语义映射或 JOIN 推理逻辑。
– 减少复杂 JOIN 推理:平台核心查询指标相同类型和维度会聚合在宽表中,JOIN 逻辑简化,从而减轻了大模型推理和结构生成负担。
综上所述,商机指标平台具备清晰的指标管理、标准化的数据模型和存储方案,极大提升了 NL2SQL 方案的实施可行性和准确率。当有新的指标接入指标平台时,这套方案无需任何开发,即可查询指标数据。
### 实现难点及解决方案
#### 难点
– 自然语言复杂性:NL2SQL 准确率问题。仅使用表 schema 进行 SQL 生成,如何准确定位多张表的多个字段?
#### 解决方案
1. 增强语义理解
– 指代消歧:用户可能使用“谁”、“人员”、“人”等含糊词汇指代“经纪人”,系统结合当前查询上下文、字段使用频率、实体别名等方式进行判别。例如:“查询昨天谁的商机量最多”,需解析为“查询昨天哪个经纪人的商机量最多”。
– 多轮对话承接与补全:对于多轮查询,如用户首次提问“查询张三商机量”,后续接着问“那他最近 7 天趋势呢?”,需承接历史语义补全主体“张三”以及指标上下文。
– 错误纠正与引导推荐:当用户提问超出系统支持指标集合或维度组合时,系统需反馈:“暂不支持‘业绩波动指数’指标,可查询‘门店业绩总额’、‘门店环比增长率’等。”并填充默认数据。例如,对于同一类型,指定默认指标。
– 例:同一类型
1. non_private_opportunity_count(非私域商机量)- 默认
2. organic_opportunity_count(自然商机量)
3. commercial_opportunity_count(商业化商机量)
4. opportunity_count(总商机量)
用户输入“查询 CCC 门店 2025 年 6 月商机量”,查询的是“CCC 门店 2025 年 6 月非私域商机量”,生成 SQL 语句:SELECT SUM(non_private_opportunity_count) AS total_non_private_opportunities FROM business_opportunity WHERE date >= ‘2025-06-01’ AND date < '2025-07-01' AND shop = 'CCC';
– 领域词义补充与转换:某些术语为行业内部通用缩写或复合指标,例如“三好经纪人”代表“响应率 > x 且转化率 > y 且商机量 > z”的组合条件。我们通过在知识库中维护这些业务语义解释,辅助模型做规则展开,生成对应的 WHERE 条件组合。
2. 提升 SQL 生成准确率
– 构建指标知识库:为每个业务指标维护其名称、口径定义、所依赖字段、所属表、维度限制等信息。系统通过召回 Top-N 相关指标,用于提示语生成或直接使用指标生成 SQL 模板。
– 处理衍生指标:对于没有直接字段映射的衍生指标(如“转成交率 = 成交量 / 商机量”),维护计算公式,并解析依赖字段及所属表信息,辅助模型根据多字段 + 表达式组合生成 SQL 语句。
– 时间格式规范化:将用户自然语言中提到的“今天”、“上周”、“近三月”等模糊时间统一转换为 Doris 兼容时间格式,如 DATE ‘2025-06-01’,避免 SQL 语法错误和执行失败。
– Few-shot 示例增强:构建覆盖常见场景(如商机量按城市分布、转化率趋势、多维度 TOP 排行等)的问题 – SQL 对,以 few-shot 方式加入 Prompt,提升大模型泛化能力与结构一致性。
3. SQL 风险控制
– 类型限制:限制仅支持 SELECT 语句执行,禁止更新、插入、删除操作,防止 SQL 注入与数据污染。例如,“更新张三商机量为 100”的 SQL 会被判定为非法。
– 语法与语义校验:执行前进行 SQL 语法解析与语义验证,确保所有字段在表结构中存在、语义逻辑合理。
– 默认限制与提示:时间范围控制:若用户未明确限定时间段,系统默认设置最近 7 天或当月范围,避免无意全表扫描;结果数量控制:若查询未设置 LIMIT,系统自动添加如 LIMIT 100 以限制数据返回量,避免过大结果影响前端加载。
– 查询计划分析与反馈:在某些关键查询场景中,系统会调用 Doris EXPLAIN 语句分析执行计划,若出现全表扫描、索引缺失等问题,给予提示并建议优化查询方式。
4
LLM与MCP Server通过工具链协同和任务流程优化,显著提升了NL2SQL的性能和可靠性。LLM负责将人为任务拆解流程自动化,采用COT方式分步执行。
MCP Server提供了多种工具,以提升SQL生成质量和完成取数逻辑。get_schema提供Doris表结构信息,帮助NL2SQL准确映射用户意图到字段;sql_query执行SQL并返回查询结果;sql_valid通过语法和语义校验,确保生成的SQL合法且安全,防止无效查询或SQL注入;sql_explain分析SQL的执行计划,识别潜在性能瓶颈,并建议优化策略。
MCP Server结合LLM的Function Calling+ReAct和Chain-of-Thought能力,优化SQL生成策略。Function Calling使LLM能够调用MCP Server的工具接口,动态获取元数据和校验结果,提升生成准确性。例如,LLM调用Schema接口确认字段类型,确保时间格式正确。COT通过分步推理,自动调整SQL生成策略。例如,面对复杂查询,COT将其分解为子任务,提高查询质量。此外,结合执行计划分析,系统自动添加性能优化条件,避免低效查询。
LLM与MCP Server的结合,将人为任务拆解流程自动化,通过COT方式实现自动化分步推理,有效解决了NL2SQL中的语义理解、表关联和查询优化难题,实现了从自然语言到高效SQL的智能转换。
为了全面测评NL2SQL的可靠性,参考了业内通用评价体系:精确匹配率和执行正确率。精确匹配率衡量生成的SQL是否与标准答案完全一致,执行正确率则关注两个查询在相同输入下是否产生相同的输出结果。为提高精确匹配率,将SQL拆解成多个模块进行对比分析,最终得出测评结果。
为全面覆盖商机指标查询场景,设计了多样化的评测集,包含问题构建和Golden SQL构建。问题构建分为三类查询:简单查询、中难度查询和语义问题查询。Golden SQL构建为每个查询提供标准SQL,确保准确性和性能。NL2SQL评估通过SQL模式对比算法和SQL执行引擎判断SQL的执行结果是否符合预期。最终,系统和人工评估后,商机指标查询场景的准确率达到93%。
LLM与MCP Server通过工具链协同和任务流程优化,显著增强了NL2SQL在商机指标平台中的性能和可靠性。COT方式将人为任务拆解流程自动化,解决了语义理解、表关联和查询优化难题。语义对齐、准确率提升和SQL风险控制确保了查询的准确性、安全性和高效性。NL2SQL评测通过多样化的评测集和模块化拆解,结合精确匹配率、执行正确率和模块准确率,精准验证了系统的性能,综合准确率达93%。相较于NL2DSL,NL2SQL开发成本低、生态成熟,完美适配单一Doris集群、指标直接映射的场景。
未来,为提升NL2SQL的适用性,计划在以下方向持续探索:构建更智能的指标检索和生成机制,通过RAG技术增强LLM的上下文理解能力;通过领域特定数据微调LLM,提升商机指标查询场景的适配性;进一步优化COT推理,处理更复杂的查询场景。这些措施将使NL2SQL进一步提升对复杂业务场景的适配能力,结合MCP Server的工具链支持,实现更智能、高效、安全的数据查询服务。
(以上内容均由Ai生成)







