美团发布Meeseeks评测基准,o3-mini领跑,DeepSeek-R1垫底引热议
发布时间:2025年8月29日
来源:szf
快速阅读: 美团M17团队推出Meeseeks评测基准,评估大模型指令遵循能力,涵盖理解任务、实现约束和遵循规则。结果显示o3-mini(high)居首,Claude3.7Sonnet第三,DeepSeek-R1和GPT-4o表现不佳。
近年来,OpenAI 的 o 系列模型、Claude3.5Sonnet 和 DeepSeek-R1 等大型语言模型迅速发展,引起广泛关注。然而,许多用户在实际应用中发现,这些模型有时未能完全遵循输入指令,导致输出内容虽好,但未满足特定格式或内容要求。为了深入研究和评估这些模型的指令遵循能力,美团 M17 团队推出新的评测基准——Meeseeks。
Meeseeks 致力于评估大模型的指令遵循能力,采用了创新的评测视角。与传统方法不同,Meeseeks 关注模型是否严格遵循用户指令,而不仅仅是回答的知识准确性。这一评测框架将指令遵循能力分为三个层次,确保评估的全面性和深度,具体包括:理解任务核心意图、实现具体约束类型和遵循细粒度规则。
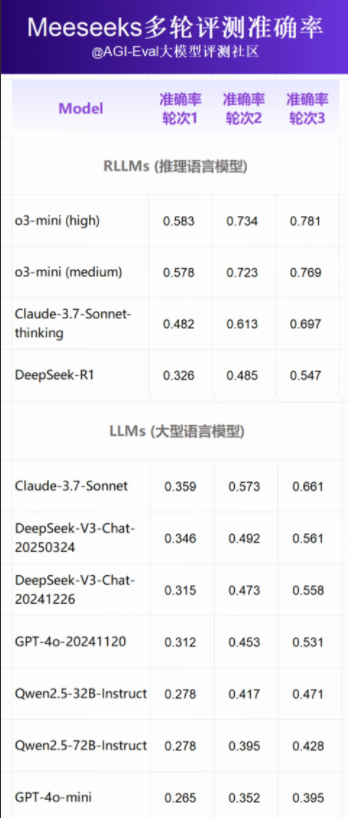
最近的评测结果显示,推理模型 o3-mini(high) 以绝对优势位居第一,o3-mini(medium) 紧随其后,Claude3.7Sonnet 稳居第三。相比之下,DeepSeek-R1 和 GPT-4o 表现不佳,分别排名第七和第八。
Meeseeks 的独特之处在于其广泛的评测覆盖面和高难度数据设计。此外,它引入了“多轮纠错”模式,允许模型在初次回答不符合要求时进行修正。这一模式显著提升了模型的自我纠错能力,特别是在多轮反馈后,所有参与模型的指令遵循准确率均有明显提高。
通过 Meeseeks 的评测,研究团队不仅揭示了不同模型间的指令遵循能力差异,还为大模型的未来研究提供了宝贵参考。
(以上内容均由Ai生成)







