NVIDIA推出Jet-Nemotron,混合架构语言模型提速53倍节省98%推理成本
快速阅读: NVIDIA发布Jet-Nemotron语言模型,生成速度提升53.6倍,推理成本降低98%,通过PostNAS技术改造现有模型,保持高准确性,适用于边缘设备。
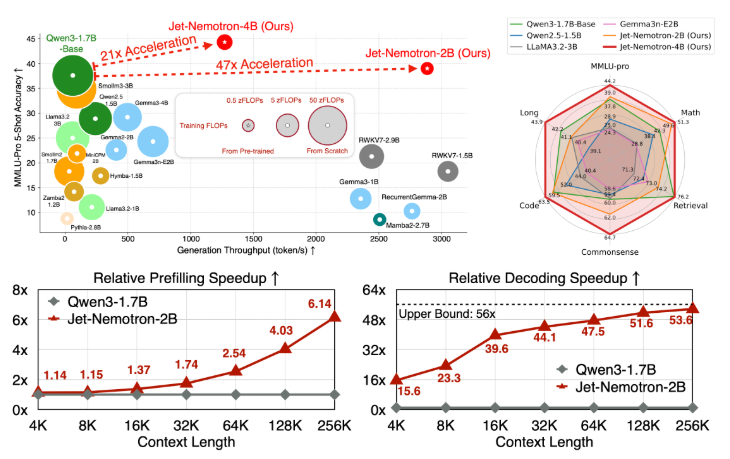
NVIDIA 研究团队近日发布了 Jet-Nemotron,这是一系列全新的语言模型,包括2亿和4亿参数的版本。这些模型的生成速度比当前最先进的全注意力语言模型高出53.6倍,并且在准确性上达到了甚至超过了这些模型的水平。这一突破是通过一种名为“后神经架构搜索”(PostNAS)的新技术实现的,而不是从头开始重新训练模型。
现代语言模型如 Qwen3、Llama3.2 和 Gemma3 虽然在准确性和灵活性上设立了新的标杆,但由于其 O(n^2) 的自注意力机制,导致计算和内存成本高昂,特别是在处理长文本任务时,这使得大规模部署变得异常昂贵,几乎无法在边缘设备或内存受限的设备上运行。尽管有一些尝试用更高效的架构替代全注意力 Transformer(如 Mamba2、GLA、RWKV 等),但在准确性上始终难以实现突破,直到现在。
PostNAS 作为 Jet-Nemotron 的核心创新,主要包含以下几个步骤:首先,选择一个最先进的全注意力模型(如 Qwen2.5),并冻结其多层感知器(MLP)层,以保护模型的学习能力并大幅降低训练成本;接着,用新的硬件高效线性注意力模块 JetBlock 替换掉计算成本高的全注意力模块;最后,通过超网络训练和束搜索,自动确定最优的全注意力层位置,从而保持在特定任务上的准确性。
Jet-Nemotron 的性能指标令人瞩目:其2B 模型在各大基准测试中与 Qwen3-1.7B-Base 相当或更优,生成吞吐量提升了47倍。同时,在256K 上下文长度下,解码速度提升53.6倍,使推理成本降低了98%。这为边缘设备的部署带来了变革性的变化。
Jet-Nemotron 的推出意味着企业能够以更低的成本实现更高的投资回报率。对于从业者而言,Jet-Nemotron 能够在不改变数据管道的情况下对现有模型进行改造,提升了实时 AI 服务的能力。对于研究人员而言,PostNAS 降低了语言模型架构创新的成本,加速了 AI 技术的发展。
项目地址:https://github.com/NVlabs/Jet-Nemotron
划重点:
– Jet-Nemotron 实现生成速度比现有模型提升53.6倍,推理成本降低98%。
– PostNAS 技术允许对现有预训练模型进行高效改造,保持准确性。
– 新模型的推出使得企业和研究者能在成本和性能上获得双重收益。
(以上内容均由Ai生成)







