DeepSeek更新推动国产芯片集体上涨
快速阅读: DeepSeek上线V3.1版本,采用混合推理架构,提升推理效率,降低成本,支持国产芯片,引发资本市场关注,概念股大幅上涨。
DeepSeek 官方上线 V3.1 版本,一条简短的留言引爆了整个 AI 圈。新的架构和下一代国产芯片,短短不到 20 字的信息量巨大,引发广泛讨论。经过科普文章的解读,可以理解为国产 AI 正逐步实现软硬件协同,未来有望减少对英伟达、AMD 等国外算力的依赖。
此次更新还打破了“性能越高成本越贵”的行业魔咒,金融、医疗等高算力应用场景的潜力显著提升。资本市场对此反应迅速,DeepSeek 宣布更新后,国产芯片概念股大幅上涨,每日互动尾盘直线拉升,收盘大涨 13.62%。有网友戏称,国产芯片迎来史诗级暴涨,DeepSeek 一句话,周五股市直冲 3800 点。
DeepSeek V3.1 版本低调上线,没有大肆宣传。这次更新的核心创新在于其混合推理架构——Hybrid Reasoning Architecture。该架构支持思考模式和非思考模式,用户可以随时切换,既可以选择详细分析,也可以快速得出结果。
此前,DeepSeek 的产品线分工明确:V3 模型擅长通用对话,R1 模型则更注重深度思考。这种分离式架构的优点是各模型在其擅长领域表现良好,但用户需要频繁切换,使用不便。如今,V3.1 打破了这一壁垒,将通用对话、复杂推理、专业编程等多种核心功能集成在同一模型中,提升了使用体验和效率。
此外,V3.1 的推理效率也有显著提升。官方数据显示,在思考模式下,V3.1 在各项任务中的平均表现与前代顶级 R1-0528 相当,但输出的 token 数量减少了 20% 至 50%。在非思考模式下,输出长度更短,但性能不打折扣。这得益于“思维链压缩”技术,使模型在训练过程中生成更简洁、高效的推理路径,确保答案准确。
为何要采取这种方式?简单来说,是为了降低成本。过去,思维链虽能增强模型推理能力,但冗长的中间步骤导致高昂的计算成本和 API 调用费用,难以大规模应用。V3.1 的思维链压缩技术解决了这一问题,使高级 AI 推理能力从学术工具变为可大规模商业化的经济方案。
在社区测试中,DeepSeek V3.1 在 Aider 多语言编程测试中的得分超过 Claude 4 Opus,且成本更低。这引起了开发者的广泛关注,Hugging Face 上的热度迅速上升。
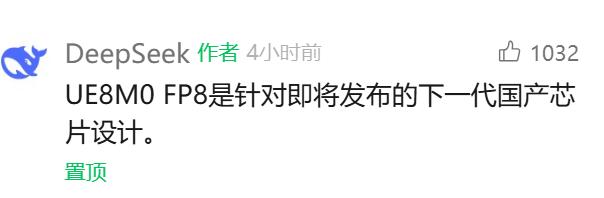
值得一提的是,DeepSeek V3.1 使用了 UE8M0 FP8 参数精度,并对分词器和聊天模板进行了调整,与之前的 V3 版本有明显区别。FP8 是一种将普通浮点数压缩为 8 位存储的技术,既节省空间又提高计算效率。MXFP8 的“块缩放”方法将数据分块,每块使用自己的缩放系数,从而在不丢失大量信息的情况下进一步节省资源。
UE8M0 中的 U、E、M 分别代表“无符号 + 指数 + 尾数”。在 UE8M0 中,所有 8 位都用于表示指数,没有尾数和符号位,这使得处理器在复原数据时更加轻松,只需移动指数位,无需复杂乘法,速度快、路径短。这种格式的另一大优势是动态范围大,能够同时表示极大和极小的数,不易溢出或归零,从而在保持 8 位张量精度的同时,将信息损失降至最低。
对于国产新芯片而言,这一技术尤为适用。目前,大多数国产 AI 芯片仍采用 FP16/INT8,无法原生支持 FP8。新一代芯片如摩尔线程 MUSA 3.1 GPU 和芯原 VIP9000 NPU 开始支持原生 FP8,DeepSeek V3.1 的 UE8M0 格式正好匹配这些硬件。总结来说,UE8M0 FP8 使模型在新一代国产芯片上运行更高效、更稳定,同时保持精度。
DeepSeek 官方确认,V3.1 版本已将 App 和网页端的“深度思考(R1)”功能更名为“深度思考”。一些网友在推特 X 上分享了新模型生成的小球跳动效果,更符合物理定律,还能调节重力、摩擦、旋转速度等参数。有人用 V3.1 制作了振动编码,甚至有人让 V3.1 为自己画了一幅自画像,风格独特。
然而,也有部分用户反映翻译和写作方面存在问题,SYSTEM PROMPT 需要现场编写指令,中英混杂和错词现象时有发生。感兴趣的用户可以登录官网自行体验。DeepSeek 每次更新都令人期待,几乎成为国产 AI 的精神图腾,让我们共同期待 DeepSeek R2 的到来。
(以上内容均由Ai生成)