Nvidia推出新型小型模型Nemotron-Nano-9B-v2,支持智能推理开关
快速阅读: Nvidia 推出 Nemotron-Nano-9B-v2 小型语言模型,参数量减少至 90 亿,专为 A10 GPU 优化,处理速度提升 6 倍,支持多语言任务,用户可灵活控制推理功能。
近日,Nvidia 推出一款新的小型语言模型 Nemotron-Nano-9B-v2,该模型在多个基准测试中表现出色,并且用户可以灵活控制其推理功能的开关。Nemotron-Nano-9B-v2 参数量为 90 亿,比其前身的 120 亿参数显著减少,旨在满足单个 Nvidia A10 GPU 的部署需求。
Nvidia AI 模型后训练总监 Oleksii Kuchiaev 表示,这款模型专为 A10 GPU 优化,能够实现高达 6 倍的处理速度,适用于多种应用场景。Nemotron-Nano-9B-v2 支持英语、德语、西班牙语、法语、意大利语、日语及扩展的韩语、葡萄牙语、俄语和中文等,适用于指令跟随和代码生成任务。
该模型基于 Nemotron-H 系列,融合了 Mamba 和 Transformer 架构,能够在处理长序列时降低内存和计算需求。与传统 Transformer 模型不同,Nemotron-H 模型采用选择性状态空间模型(SSM),在保证准确性的同时,高效处理更长的信息序列。
在推理功能方面,Nemotron-Nano-9B-v2 默认生成推理过程的跟踪记录,用户可以通过简单的控制指令,如 /think 或 /no_think,来切换这一功能。此外,模型引入了运行时“思考预算”管理,允许开发者设定最大 token 数量,以在准确性和响应速度之间取得平衡。
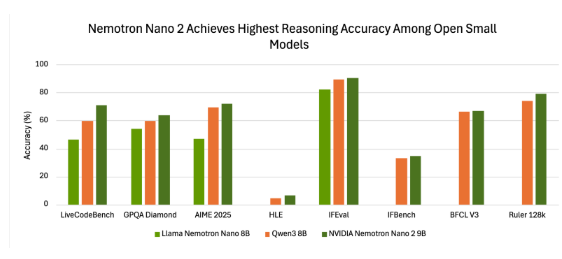
在基准测试中,Nemotron-Nano-9B-v2 展现了良好的准确性。例如,在使用 NeMo-Skills 套件的“推理开启”模式下,该模型在多个测试中均表现出色,显示出与其他小型开源模型相比的优势。
Nvidia 以开放模型许可证发布了 Nemotron-Nano-9B-v2,允许商业用途,开发者可自由创建和分发衍生模型。值得注意的是,Nvidia 不对模型生成的输出主张所有权,用户可完全控制其使用。
该模型的发布旨在为开发者提供在小规模环境中平衡推理能力和部署效率的工具,标志着 Nvidia 在提高语言模型效率和可控推理能力方面的持续努力。
huggingface: https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-9B-v2
划重点:🌟 Nvidia 推出新型小型语言模型 Nemotron-Nano-9B-v2,支持用户灵活控制推理功能。
⚙️ 该模型基于先进的混合架构,能够高效处理长序列信息,适用于多语言任务。
📊 Nemotron-Nano-9B-v2 以开放模型许可证发布,允许开发者进行商业用途和衍生模型的创建。
(以上内容均由Ai生成)







