腾讯发布AudioGenie,一键生成电影级音效,竞品颤抖
快速阅读: 腾讯AI Lab推出多模态音频生成工具AudioGenie,无需训练即可生成高质量音效、语音、音乐,支持视频、文本、图像输入,重塑全球AI音频市场,提升中国AI竞争力。
随着人工智能技术的飞速发展,腾讯AI Lab推出了一款创新的多模态音频生成工具——AudioGenie。这款工具以其自然贴切的生成效果、强大的上下文理解能力以及无需训练的特性,正在重塑全球AI音频市场格局。
AudioGenie支持视频、文本和图像等多种模态输入,能够生成音效、语音、音乐以及混合音频输出。无论是在影视作品中生成沉浸式背景音乐、为虚拟人物配音,还是为游戏场景添加逼真的环境音效,AudioGenie都能轻松应对。其生成效果不仅自然流畅,还能高度贴合输入内容的上下文,展现出卓越的语义理解能力。实验表明,AudioGenie在视频到多音频生成、文本到多音频生成等任务中,均达到或超越了行业领先水平。
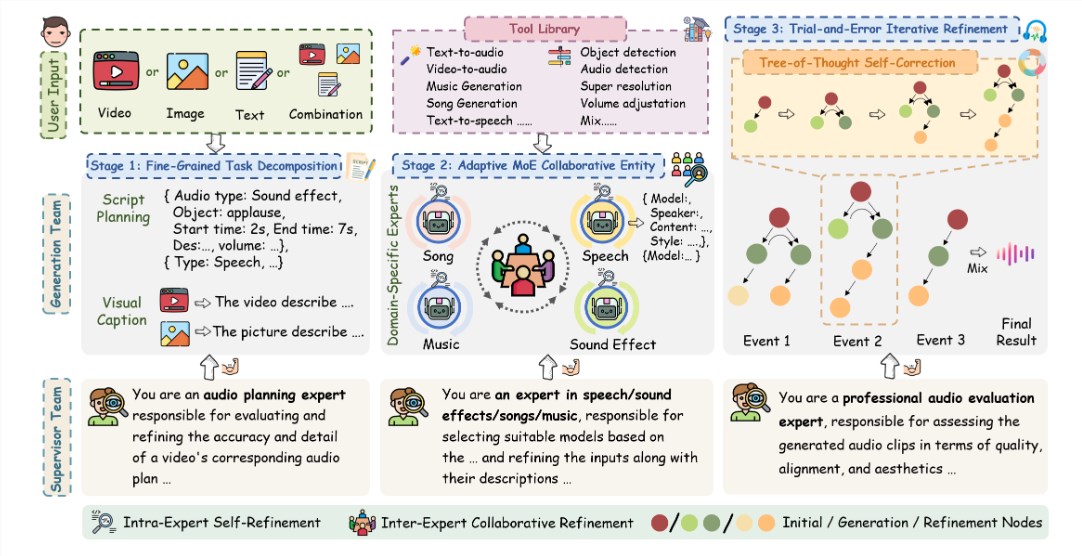
与传统音频生成模型需要大量训练数据不同,AudioGenie采用创新的无训练多智能体框架,通过双层架构(生成团队与监督团队)实现高效协同。生成团队通过细粒度任务分解和自适应专家混合(MoE)机制,动态选择最适合的模型进行音频生成,确保输出质量。监督团队则负责时空一致性验证,并通过反馈循环进行自我纠错,确保生成的音频高度可靠。这一设计彻底消除了对大规模配对数据集的依赖,极大降低了开发成本,同时提升了生成效率。
为了全面评估多模态音频生成能力,腾讯AI Lab推出了MA-Bench,这是全球首个针对多模态到多音频生成(MM2MA)任务的基准测试集,包含198个带有多类型音频注释的视频。测试结果显示,AudioGenie在9项指标、8项任务中均达到或接近最先进水平(SOTA),尤其在音质、准确性、内容对齐和美学体验方面表现突出。用户调研进一步验证了其在实际应用中的优越性,为游戏开发、影视制作和虚拟现实等场景提供了强大支持。
AudioGenie的发布不仅为用户带来了高效便捷的音频生成体验,也对现有市场格局构成挑战。结合近期数据,国产AI模型如Qwen3、Kimi-K2和GLM-4.5在全球市场的快速崛起,AudioGenie的加入进一步巩固了中国AI企业的竞争力。OpenRouter数据显示,Qwen3使用量增长15.4%,而Claude和Gemini分别下降18.9%和6.8%。AudioGenie凭借其多模态能力和高性价比,有望进一步挤压国际巨头的市场份额。
未来展望:AudioGenie的推出标志着AI音频生成技术迈向新高度。其多模态输入、无需训练和自我纠错的特性,为创作者提供了前所未有的灵活性和效率。业内人士预测,AudioGenie将在媒体制作、游戏开发和无障碍工具等领域引发广泛应用,助力中国AI技术在全球舞台上大放异彩。AIbase将持续关注AudioGenie的最新动态,为您带来第一手行业资讯。
总结:腾讯AudioGenie以其强大的多模态音频生成能力和创新的无训练框架,正在重新定义AI音频生成的标准。面对国际巨头的竞争,AudioGenie展现了中国AI技术的硬核实力。AIbase将持续跟踪这一领域的最新进展,为您揭秘AI如何改变创作未来!项目地址:https://audiogenie.github.io/
(以上内容均由Ai生成)







