政府宣布新环保措施,力争2030年前碳排放达峰
快速阅读: 英伟达推出Nemotron-Nano-9B-V2小型语言模型,性能优越,支持多语言和推理功能开关,适用于多种任务,现已在Hugging Face和英伟达模型目录中提供。
英伟达推出小型语言模型Nemotron-Nano-9B-V2,性能在同类产品中名列前茅,并支持用户开关AI“推理”功能,即在输出答案前进行自我检查。尽管该模型的90亿参数量大于近期VentureBeat报道的一些数百万参数的小型模型,但英伟达指出,这已经是从最初的120亿参数大幅削减的结果,旨在适配单个Nvidia A10 GPU。
Nvidia AI模型后训练总监Oleksii Kuchiaev在X平台上回应提问时表示:“120亿参数的模型经过剪枝至90亿,以适应广泛用于部署的A10 GPU。此外,它还是一个混合模型,能够处理更大的批次,速度比类似大小的Transformer模型快6倍。”
Nemotron-Nano-9B-V2支持多种语言,包括英语、德语、西班牙语、法语、意大利语、日语、韩语、葡萄牙语、俄语和中文,适用于指令执行和代码生成任务。该模型基于Nemotron-H架构,融合了Transformer和Mamba架构,后者由卡内基梅隆大学和普林斯顿大学的研究人员开发,能够在处理长序列信息时保持状态,从而实现线性扩展,减少内存和计算开销。
用户可以通过简单的控制标记如/think或/no_think来开启或关闭推理功能,模型还引入了运行时“思考预算”管理机制,允许开发者限制内部推理所使用的令牌数量,以平衡准确性和延迟,尤其适合客户服务和自主代理应用。
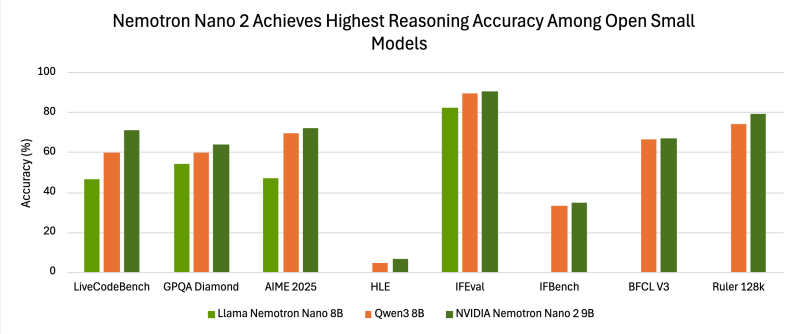
评估结果显示,Nemotron-Nano-9B-V2在多个基准测试中表现出色,例如在NeMo-Skills套件中,其在AIME25上达到72.1%,MATH500上达到97.8%,GPQA上达到64.0%,LiveCodeBench上达到71.1%。在指令跟随和长上下文基准测试中,成绩分别为IFEval上的90.3%和RULER 128K测试上的78.9%。总体而言,Nano-9B-v2在多项指标上优于Qwen3-8B等竞品。
英伟达通过准确率与预算曲线展示了性能随推理令牌增加的变化趋势,建议开发者通过精细控制预算,在实际应用中同时优化质量和延迟。该模型现已在Hugging Face和英伟达模型目录中提供。
英伟达确认,Nano 模型和 Nemotron-H 系列均依赖于精选、网络来源和合成训练数据的混合体。这些语料库包括普通文本、代码、数学、科学、法律和金融文件,以及对齐式问答数据集。英伟达还使用其他大型模型生成的合成推理轨迹来增强在复杂基准测试中的表现。
英伟达发布的 Nano-9B-v2 模型采用《英伟达开放模型许可协议》,最新更新时间为 2025 年 6 月。该许可旨在宽松且对企业友好。英伟达明确表示,这些模型可以直接商用,开发者可以自由创建和分发衍生模型。重要的是,英伟达不对模型生成的任何输出主张所有权,将责任和权利归于使用模型的开发者或组织。
对于企业开发者来说,这意味着模型可以立即投入生产,无需单独谈判商业许可或支付与使用量、收入水平或用户数量相关的费用。即使公司达到一定规模,也不需要付费许可证,这与一些其他提供商使用的分层开放许可不同。
然而,协议中包含几项企业必须遵守的条件:
– **安全机制**:用户不得绕过或禁用内置的安全机制(称为“护栏”),除非实施同等或更高级别的替代措施。
– **再分发**:任何模型或衍生产品的再分发必须包含英伟达开放模型许可文本和归属声明(“由英伟达公司根据英伟达开放模型许可授权”)。
– **合规性**:用户必须遵守贸易法规和限制(例如,美国出口法)。
– **可信 AI 条款**:使用必须符合英伟达可信 AI 准则,涵盖负责任的部署和伦理考虑。
– **诉讼条款**:如果用户因模型侵权而对另一方提起版权或专利诉讼,许可自动终止。
这些条件侧重于合法和负责任的使用,而非商业规模。企业无需因构建产品、货币化或扩大用户基础而向英伟达寻求额外许可或支付版税。相反,他们必须确保部署实践符合安全、归属和合规义务。
在市场定位上,英伟达针对需要在较小规模下平衡推理能力和部署效率的开发者推出了 Nemotron-Nano-9B-v2。运行时预算控制和推理切换功能旨在为系统构建者提供管理准确性和响应速度的灵活性。该模型在 Hugging Face 和英伟达模型目录上的发布表明,它们旨在广泛用于实验和集成。
英伟达发布 Nemotron-Nano-9B-v2 展现了其在语言模型效率和可控推理方面的持续关注。通过结合混合架构和新的压缩及训练技术,英伟达为开发者提供了在降低成本和延迟的同时保持准确性的工具。
(以上内容均由Ai生成)







