腾讯发布混元开源模型,涵盖0.5B至7B参数量

快速阅读: 近日,腾讯混元团队发布四款小尺寸开源模型,参数分别为0.5B、1.8B、4B和7B,专为消费级显卡设计,适用于低功耗场景,支持低成本微调,丰富了开源模型体系,已在多个业务中应用,提升效率和准确性。
近日,腾讯混元团队发布了四款开源小尺寸模型,参数分别为0.5B、1.8B、4B和7B。这些模型专为消费级显卡设计,适用于笔记本电脑、手机、智能座舱、智能家居等低功耗场景,并支持垂直领域的低成本微调。此举进一步丰富了混元开源模型体系,为开发者和企业提供了更多尺寸的模型选择。
腾讯混元大模型持续开源的一部分,旨在为开发者和企业提供更多选择,以满足不同场景的需求。目前,这些模型已在GitHub和HuggingFace等开源社区上线,并获得了Arm、高通、Intel、联发科技等多个消费级终端芯片平台的支持。
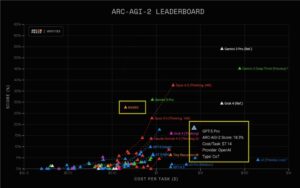
新推出的四个模型属于融合推理模型,具备推理速度快、性价比高的特点。用户可根据使用场景灵活选择模型的思考模式:快思考模式提供简洁、高效的输出,适合简单任务;慢思考模式则涉及解决复杂问题,具备更全面的推理步骤。在效果上,这些模型在语言理解、数学、推理等领域表现出色,在多个公开测试集上得分达到领先水平。
这四个模型的亮点在于其Agent能力和长文处理能力。通过精心的数据构建和强化学习奖励信号设计,这些模型在任务规划、工具调用和复杂决策以及反思等Agent能力上表现出色,能够轻松胜任深度搜索、Excel操作、旅行攻略规划等任务。此外,模型原生长上下文窗口达到256K,意味着模型可以一次性记住并处理相当于40万中文汉字或50万英文单词的超长内容,相当于一口气读完3本《哈利波特》小说,并记住所有人物关系和剧情细节,还能根据这些内容讨论后续故事发展。
在部署方面,这四个模型均只需单卡即可部署,部分PC、手机、平板等设备可直接接入。模型具有较强的开放性,主流推理框架(如SGLang、vLLM和TensorRT-LLM)和多种量化格式均能支持。
应用层面,这四款小尺寸模型能够满足从端侧到云端、从通用到专业的多样化需求,已在腾讯多个业务中应用,其可用性和实用性经过了实践检验。例如,依托模型原生的超长上下文能力,腾讯会议AI小助手和微信读书AI助手实现了对完整会议内容和整本书籍的一次性理解和处理。在端侧应用上,腾讯手机管家利用小尺寸模型提升垃圾短信识别准确率,实现毫秒级拦截,隐私零上传;腾讯智能座舱助手通过双模型协作架构解决车载环境痛点,充分发挥模型低功耗、高效推理的特性。
(以上内容均由Ai生成)