Deep Cogito 做大,发布 4 个具有自我改进“直觉”的新开源混合推理模型
快速阅读: 据《风险节拍》称,旧金山Deep Cogito公司发布Cogito v2系列四个大模型,参数量从70B到671B不等,具备自我改进能力,采用混合授权方式。其旗舰模型671B在基准测试中表现优异,支持FP8版本,降低计算需求。
记者获悉,4月,旧金山,Deep Cogito公司发布了四个新的大型语言模型(LLM),这些模型具备自我改进能力,能够更高效地进行推理。这些模型作为Cogito v2系列的一部分,参数量从700亿到6710亿不等,面向人工智能开发者和企业推出,采用有限授权和完全开放授权相结合的方式。
Cogito v2系列包括四种型号:70B密集型、109B专家混合型、405B密集型和671B MoE。密集型模型在每次前向传递时激活所有参数,适合低延迟应用和微调;MoE模型使用稀疏路由机制,仅激活特定子网络,适用于高性能推理任务和复杂研究。
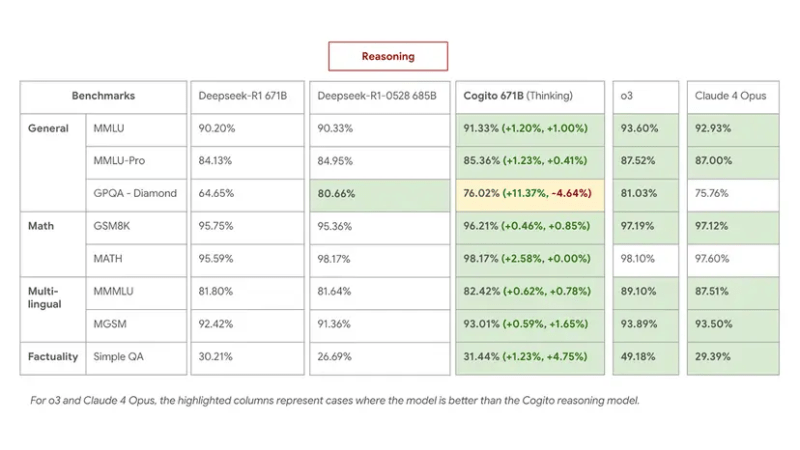
旗舰产品671B MoE模型在基准测试中表现出色,与领先的开源模型相媲美甚至超越,同时使用更短的推理链。此外,还推出了8位浮点数(FP8)版本的671B模型,大幅减少了计算资源需求,性能损失极小。
Deep Cogito的核心技术在于迭代蒸馏和放大(IDA),通过模型自身不断演进的见解替代手动编写的提示或静态教师。这种方法使得模型在训练过程中不断优化推理路径,提高推理效率和整体性能。
公司首席执行官Drishan Arora表示,Cogito v2的目标是构建能够随每次迭代而推理和改进的模型,类似于AlphaGo通过自我对弈优化策略。这一方法在内部测试中取得了显著成果,特别是在数学计算、法律推理和处理歧义方面。
Deep Cogito的所有模型均可在Hugging Face和Unsloth平台上下载使用,或通过Together AI、Baseten和RunPod的API访问。这些模型不仅提供了强大的性能,还在成本和效率上表现出色,为开发者和企业提供了一个新的选择。
(以上内容均由Ai生成)







