阶跃星辰最新一代基础大模型 Step 3 正式开源
快速阅读: 据《AIbase – AI新闻资讯》称,7月11日,阶跃星辰团队宣布其最新一代基础大模型 Step3 正式开源。Step3 采用 MoE 架构,总参数量达 3210 亿,具备强大的视觉感知和复杂推理能力,支持跨领域复杂知识理解及日常视觉分析。该模型在各类芯片上的推理效率显著提升,已在 GitHub、Hugging Face 和魔搭 ModelScope 开源。
阶跃星辰团队宣布其最新一代基础大模型 Step3 正式开源。Step3 是一款专为追求性能与成本均衡的企业和开发者设计的模型,旨在为推理时代打造最适用的模型。该模型的开源地址包括 Github、Hugging Face 和魔搭 ModelScope,开发者可以自由下载体验。
Step3 采用 MoE 架构,总参数量达到 3210 亿,激活参数量为 380 亿。这款模型不仅具备强大的视觉感知和复杂推理能力,还能准确完成跨领域复杂知识理解、数学与视觉信息的交叉分析及日常视觉分析问题。通过 MFA(多矩阵分解注意力)和 AFD(注意力-前馈网络分离)的优化,Step3 在各类芯片上的推理效率均有显著提升。此外,面向 AFD 场景的 StepMesh 通信库也已随模型一同开源,提供跨硬件的标准部署接口,支持关键性能在实际服务中的稳定复现。
Step3 的核心结构采用了自主研发的 MFA 注意力机制,有效降低了注意力计算中的 KV 缓存开销与算力消耗。在不牺牲模型能力的前提下,这一方案实现了资源利用与推理效率的平衡,使模型能够在 8×48GB 显卡上完成大吞吐量推理,具有实际部署的可行性。在多模态能力方面,Step3 采用 5B 视觉编码器,并通过双层 2D 卷积对视觉特征进行降采样,将视觉 token 数量减少到原来的 1/16,从而减轻上下文长度的压力,提高推理效率。训练过程分为两个阶段:第一阶段强化编码器感知,第二阶段冻结视觉编码器,仅优化主干与连接层,以减少梯度干扰。训练语料涵盖配对、交织与多任务数据,在清洗环节中引入相似度过滤、重采样与任务比例控制,进一步提升了图文协同质量和训练鲁棒性。
Step3 在系统架构层面对解码流程进行了重构,重点解决了注意力与前馈网络混合执行导致的推理瓶颈及资源不匹配问题。团队实现了高性能的 AFD 方案,将两类计算任务解耦成两个子系统,并通过多级流水线并行调度,有效提升了整体吞吐效率。由于解耦后的子系统间对数据传输有极高要求,团队还研发了面向 AFD 场景的 StepMesh 通信库,基于 GPU Direct RDMA 实现跨卡的低延迟和高带宽传输,同时具备不占用 GPU 计算资源、适应多种异构硬件的优势。在 50ms 解码的 SLA 前提下,Step3 在 Hopper GPU 上的吞吐率达到 4039token/gpu/s,显著高于类似设置下的 DeepSeek V3(2324token/gpu/s),且该性能增益在特定硬件与长文场景中将进一步放大至 300%。
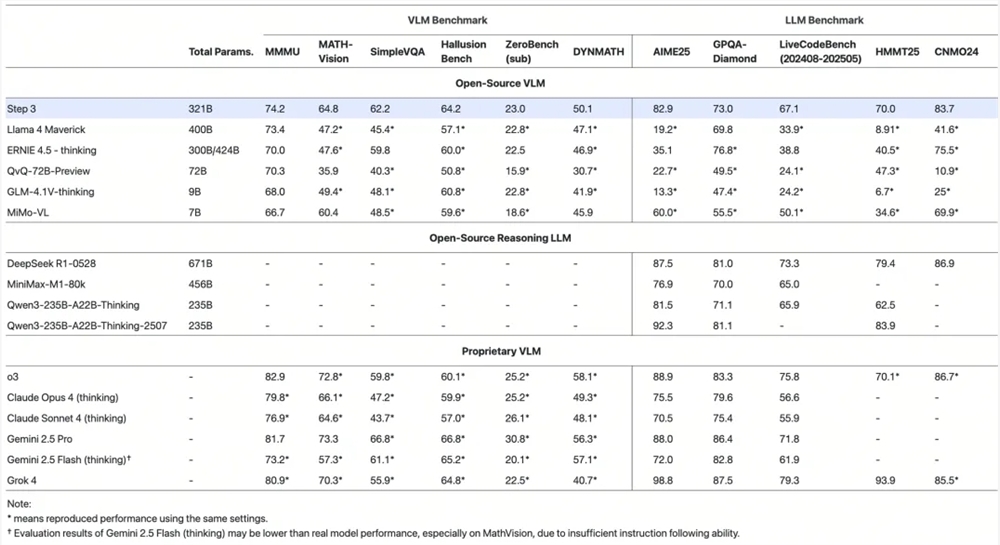
Step3 在 MMMU、MathVision、SimpleVQA、AIME2025、GPQA-Diamond、LiveCodeBench(2024.08-2025.05)等评测集上进行了测试,在同类型开源模型中,Step3 成绩领先。例如,在“安排商务宴座”的任务中,Step3 能够识别图中结构,自动解析礼仪规则、角色关系与空间逻辑,结合中文社交礼仪推理出完整的 12 人角色分布逻辑,最终输出角色明确、位置清晰、结构合理的“主宾-主陪”全局排座方案,并用表格加 ASCII 图直观展示。在卡路里计算任务中,Step3 能够读懂复杂的小票,将菜品分类、匹配热量,最终估算出两人一顿饭共摄入 5710 卡路里,人均 2855 卡路里,整个过程从原始数据到结论解释,逻辑清晰,形成闭环。
Step3 API 已上线阶跃星辰开放平台(platform.stepfun.com),开发者也可在“阶跃 AI”官网(stepfun.com)和“阶跃 AI”App(应用商店搜索下载)进行体验。模型限时折扣中,所有请求均按最低价格计算,每百万 token 输入价格为 1.5 元,输出价格为 4 元。
GitHub:https://github.com/stepfun-ai/Step3
Hugging Face:https://huggingface.co/stepfun-ai/step3
魔搭 ModelScope:https://www.modelscope.cn/models/stepfun-ai/step3
https://www.modelscope.cn/models/stepfun-ai/step3-fp8
(以上内容均由Ai生成)







