微软发布 DragonV2.1:AI 语音转录更自然,错误率下降 12.8%
发布时间:2025年7月31日
来源:szf
快速阅读: 据《IT之家 – 电脑频道》称,7月31日,微软推出 DragonV2.1Neural 零次学习模型,仅需少量数据即可生成自然、表现力强的语音,支持超过100种语言。新模型提高了发音准确性和声音自然度,适用于定制聊天机器人声音和多语言视频配音。相比上一代,单词错误率平均降低12.8%。
IT之家 7 月 31 日消息,科技媒体 NeoWin 今天(7 月 31 日)发布博文,报道称微软推出了 DragonV2.1Neural 零次学习(Zero-Shot Learning)模型, 仅凭少量数据就能创建更加自然、表现力强的声音,并支持超过 100 种语言。
IT之家援引博文介绍,这是一种零次学习的文本到语音(TTS)模型,承诺提供更加自然和富有表现力的声音,并提高了发音的准确性以及增强了可控性。
新模型仅需几秒钟的语音样本即可合成超过 100 种语言的语音。相比之下,之前的 DragonV1 模型在处理专有名词时存在发音问题。DragonV2.1 模型可以应用于多种不同场景,包括定制聊天机器人声音和为视频内容跨多语言配音。
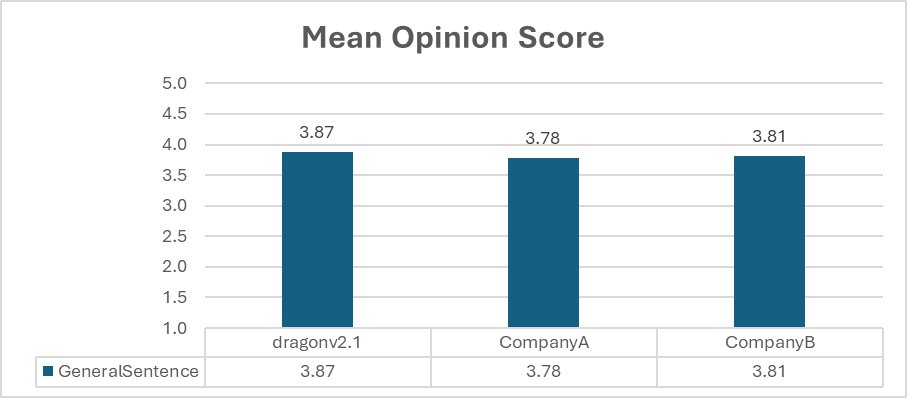
微软表示,DragonV2.1 提高发音准确性,与 DragonV1 相比,该模型单词错误率(WER)平均降低了 12.8%。
该模型还提升了声音的自然度,用户使用此模型时,可以利用 SSML 音素标签和自定义词典对发音和口音进行细致控制。为了帮助用户入门,微软构建了 Andrew、Ava 和 Brian 等多个声音档案,供用户测试。
(以上内容均由Ai生成)







