苹果与剑桥大学合作设计AI评审框架 突破复杂任务评审限制
发布时间:2025年7月24日
来源:szf
快速阅读: 据相关媒体最新报道,苹果与剑桥大学合作开发新AI评估系统,引入外部工具提升复杂任务的评审质量。该系统通过事实核查、代码执行和数学验证工具,增强AI评审能力。
据科技媒体 NeoWin 报道,7月24日,苹果公司与剑桥大学合作,提出了一种新的 AI 评估系统,通过引入外部验证工具增强 AI 评审员的能力,以提高评审质量。
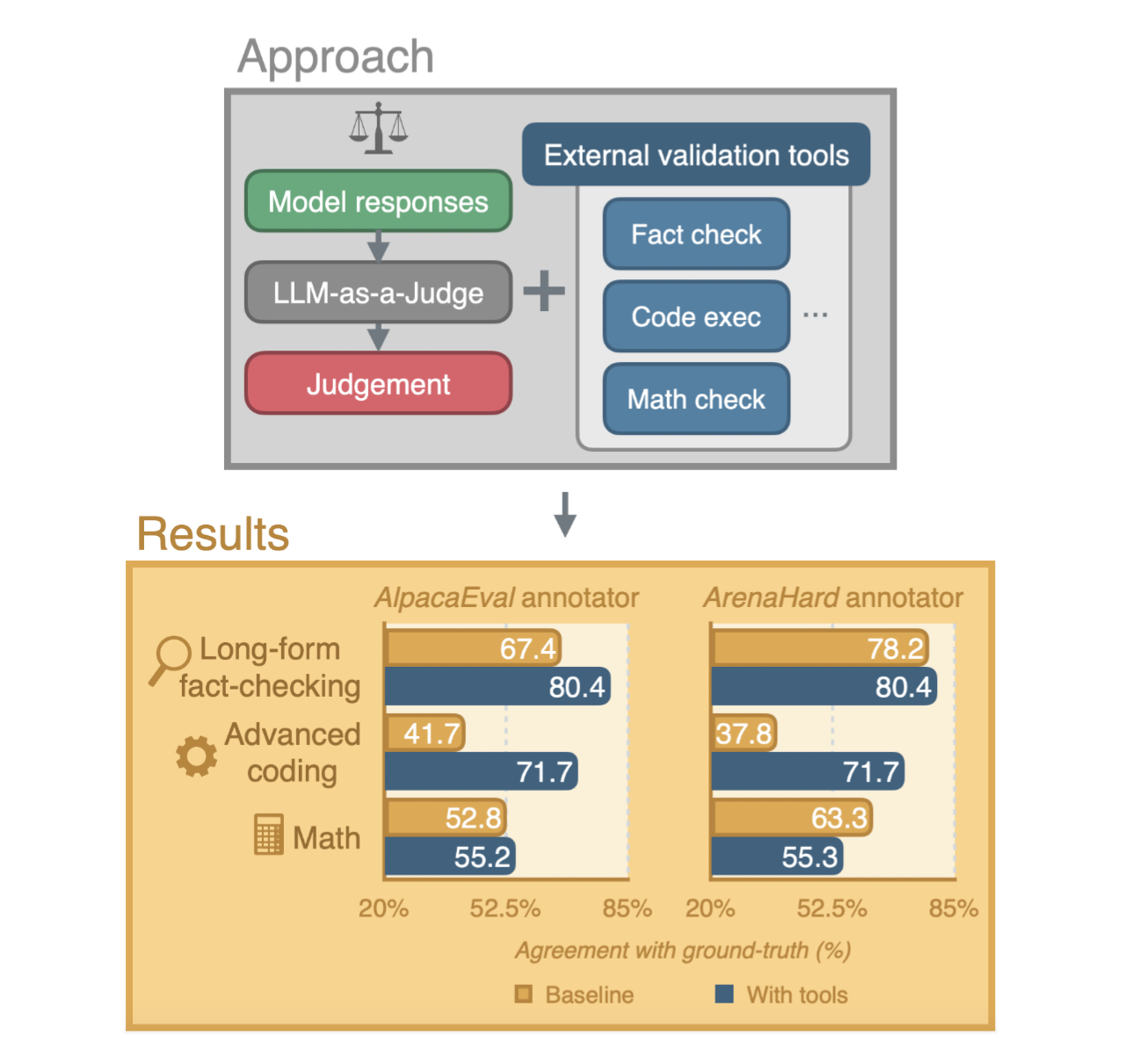
在评估大语言模型(LLM)时,研究人员和开发者越来越依赖 AI 进行评审,即所谓的“LLM-as-a-judge”方法。然而,这种方法在处理长篇事实核查、高级编程和数学问题等复杂任务时,评估质量会有所下降。
苹果与剑桥大学联合发布的一篇研究论文中,介绍了一种新系统,通过为 AI 评审员配备外部验证工具,克服了人类和 AI 注释中的局限性。人类评审员因时间限制、疲劳及偏好写作风格而非事实准确性等问题,面临挑战和偏见;而 AI 在处理复杂任务时也存在困难。
研究人员开发的评估代理具有自主性,能评估响应并决定是否需要使用外部工具,以及使用哪种工具。评估过程分为三个主要步骤:初步领域评估、工具使用和最终决策。其中,事实核查工具通过网络搜索验证原子事实;代码执行工具利用 OpenAI 的代码解释器运行并验证代码的正确性;数学核查工具则是代码执行工具的一个专门版本,用于验证数学和算术运算。
当系统判断无需工具辅助时,将使用基础 LLM 注释器,以避免在简单任务上的过度处理和可能的性能下降。
(以上内容均由AI生成)







