阿尔茨海默病遗传学中的机器学习
发布时间:2025年7月22日
来源:szf
快速阅读: 据《Nature.com》称,研究利用机器学习分析医学数据,未预设样本量,采用统一质量控制和数据划分。模型包含或排除APOE区域SNP,调整协变量后在测试集验证,结果稳定。
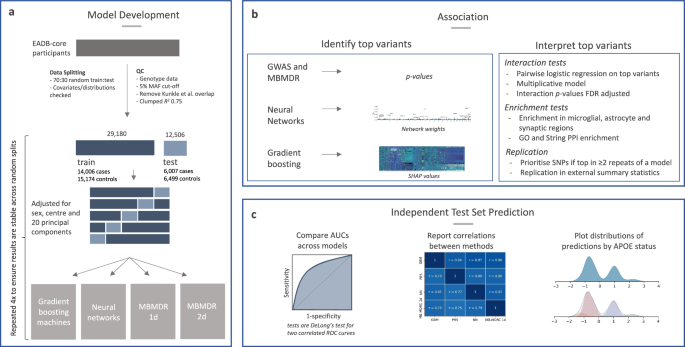
记者了解到,近日,一项关于机器学习在医学研究中应用的研究取得了进展。该研究没有预先确定样本量,因为机器学习缺乏标准化的计算方法。为了确保一致性,所有方法均采用了相同的质量控制和随机训练-测试数据划分(如图1所示)。研究对象在病例对照状态、年龄、性别、基因分型中心及主要成分的分布上保持平衡(详见补充图2)。
参与者被随机分为70%的训练集和30%的测试集,其中训练集包含29,180名个体(14,006例病例;15,174例对照),测试集包含12,506名个体(6,007例病例;6,499例对照)。每位个体的数据包含215,193个预测变量。
研究团队构建了两组机器学习模型,一组包含来自APOE区域的SNP数据,另一组则不包含。在训练过程中,分析中考虑了遗传性别、20个主成分和基因分型中心等协变量,并根据不同的建模方法进行了适当的调整。例如,神经网络中协变量被纳入最终层,而梯度提升机和MB-MDR则先对协变量进行z变换,再从数据中去除。
所有模型的受试者工作特征曲线下面积(AUC)值均基于预测概率计算,并在测试集中调整了混杂因素。为了减少过拟合的风险,研究采用了惩罚机制与交叉验证的随机搜索(适用于梯度提升机)或基于网格的搜索(适用于神经网络和MB-MDR)。
研究团队还通过在三个额外的70%-30%训练-测试划分上重新运行所有模型,进一步验证了结果的稳定性。详细的训练过程及协变量调整信息可参见补充部分1.2至1.4。
(以上内容均由Ai生成)







