Mistral推出Voxtral 开源AI音频新时代来临
快速阅读: 据相关媒体报道,法国初创公司Mistral发布开源音频模型Voxtral,支持多语言,可转录30分钟音频,性能优于Whisper,价格更低,助力开发者打破大厂垄断。
据AIbase – AI新闻资讯报道,9月15日,法国巴黎,初创企业Mistral正式发布了其首个开源音频模型——Voxtral,旨在打破大型企业封闭系统的垄断,为开发者提供更灵活且经济的替代方案。
Mistral表示,Voxtral是首个能在实际应用中提供“真正可用的语音智能”的开源模型。这使得开发者无需在低成本的开源系统和高效但封闭的解决方案之间做出艰难选择。Voxtral凭借其“不到一半价格”的优势,为企业提供了更为经济的选择。
据介绍,Voxtral可以转录长达30分钟的音频,由于基于大型语言模型Mistral Small3.1,用户能够理解最长40分钟的音频内容。用户不仅能对音频内容提问,还能生成摘要,甚至将语音指令转化为实时操作,如调用API或执行特定功能。此外,Voxtral支持多语言,包括英语、西班牙语、法语、葡萄牙语、印地语、德语、荷兰语和意大利语等。
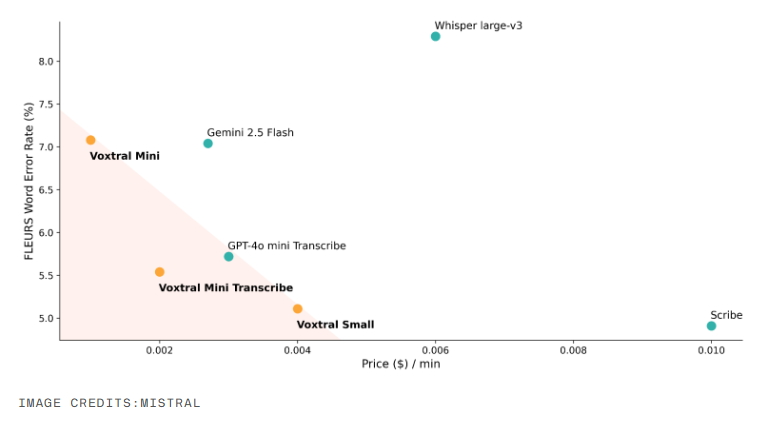
Mistral提供了两种“语音理解模型”的变体。首先是Voxtral Small,拥有240亿个参数,适合生产级部署,与ElevenLabs Scribe、GPT-4o-mini和Gemini2.5Flash等竞争。其次是Voxtral Mini,具有30亿个参数,适用于本地和边缘部署。还有一款超经济版的3亿参数模型,称为Voxtral Mini Transcribe,专为转录场景优化,性能超越OpenAI的Whisper,价格却不到其一半。
用户可通过Hugging Face免费下载Voxtral的API,或在Mistral的聊天机器人Le Chat中进行测试。API的集成费用从每分钟0.001美元起。此次发布正值Mistral一个月前推出推理模型Magistral,这些模型通过逐步解决问题来提高可靠性。
作为欧洲顶尖的人工智能公司之一,Mistral一直致力于推动开源AI模型的发展。有消息称,Mistral正在与投资者洽谈,计划筹集高达10亿美元的资金,其中包括阿布扎比的MGX基金。
(以上内容均由AI生成)







