字节跳动开源POLARIS模型 数学推理能力媲美235B参数模型
快速阅读: 据相关媒体报道,字节跳动联合港大、复旦推出POLARIS强化学习方法,提升小模型数学推理能力,性能媲美大模型,支持消费级显卡运行,已开源。
据AIbase – AI新闻资讯报道,近日,字节跳动Seed团队联合香港大学与复旦大学,推出了一种新的强化学习训练方法——POLARIS。该方法通过独特的Scaling RL策略,成功提升了小模型的数学推理能力,达到与超大模型相当的水平,为小模型优化开辟了新途径。
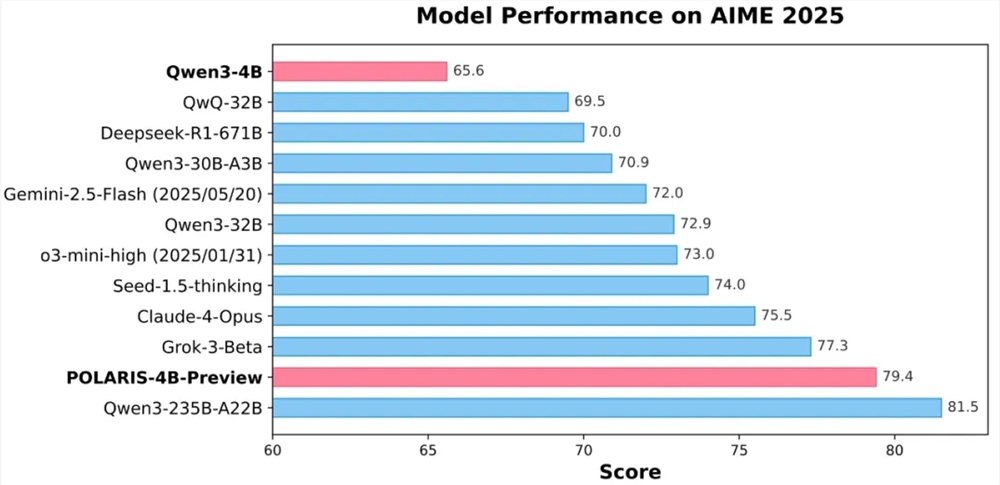
实验表明,采用POLARIS训练的40亿参数开源模型Qwen3-4B,在AIME25和AIME24数学测试中分别获得了79.4%和81.2%的高准确率,性能超过了一些更大的闭源模型。特别值得一提的是,POLARIS-4B模型的轻量化设计,使其能够在普通消费级显卡上运行,大大降低了应用门槛。
POLARIS的核心创新在于其训练策略。研究团队发现,通过定制化训练数据和超参数设置,可以显著增强小模型的数学推理能力。具体来说,团队动态调整了训练数据的难度分布,构建了偏重难题的数据集,避免了样本难度过于集中。同时,引入了数据动态更新机制,根据模型在训练过程中的表现实时剔除过易样本,确保训练效果。
在采样控制方面,POLARIS通过精确调节采样温度,平衡了模型性能与生成路径的多样性。研究表明,采样温度对模型性能和路径多样性有显著影响,过高或过低的温度都不利于训练。因此,团队提出了一种控制探索区域的温度初始化方法,并在训练过程中动态调整采样温度,以保持生成内容的多样性。
针对长上下文训练的挑战,POLARIS引入了长度外推技术,通过调整位置编码RoPE,使模型能够处理超出训练时所见的更长序列。这一策略有效弥补了长文本训练中的不足,提高了模型在长文本生成任务上的表现。
此外,POLARIS还采用了多阶段RL训练方法,初期使用较短的上下文窗口进行训练,待模型表现稳定后逐渐增加上下文窗口长度。这一策略有助于模型逐步适应更复杂的推理任务,提升了训练的稳定性和效果。
目前,POLARIS的训练方法、训练数据、训练代码和实验模型已全部开源。研究团队在多个主流推理评测集上验证了POLARIS的有效性,结果显示,不同规模和家族的模型在应用POLARIS训练方法后,性能均有显著提升。
GitHub主页:https://github.com/ChenxinAn-fdu/POLARIS
Hugging Face主页:https://huggingface.co/POLARIS-Project
(以上内容均由AI生成)