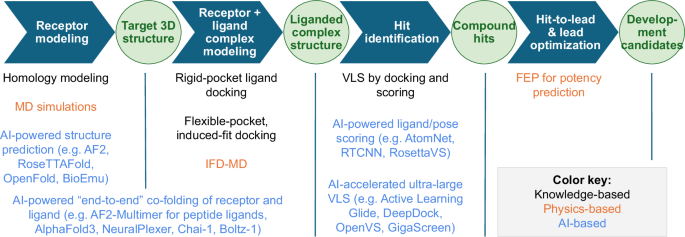
AI 在基于计算结构的 GPCR 药物发现中与物理学相结合
快速阅读: 据《Nature.com》最新报道,第一步结合多种受体模型与对接方法构建复合物模型;第二步通过RB-FEP评估模型准确性,分阶段筛选高精度模型。若多个模型表现良好,可通过聚类分析确定最优模型,进一步验证其预测能力。
在第一步(1)中,通过将多个受体模型(包括实验结构以及来自同源建模或基于人工智能的方法如AlphaFold2的相关模型)与每个起始受体构象的诱导契合对接相结合,构建出一组受体-配体结构模型。
在第二步(2)中,对每个受体-配体复合物模型进行评估,以检验其是否能够通过RB-FEP(灰色箭头)回顾性预测感兴趣配体周围的构效关系。为了提高效率,可以分步骤进行,即采用可用构效关系数据的一个较小的、精选子集,对所有模型进行快速初步评估,只有在该阶段具有较高准确性的模型才会在更大的数据集上进一步验证。如果构效关系数据允许的话,结果还可以按配体修饰区域进行细分,并利用RB-FEP提供更细致的见解,即哪些区域具有预测性(小彩色方块)。
为了提高效率,可以分步骤进行,即采用可用构效关系数据的一个较小的、精选子集,对所有模型进行快速初步评估,只有在该阶段具有较高准确性的模型才会在更大的数据集上进一步验证。
通常情况下,当多个模型显示出良好的RB-FEP准确性时,它们通常基于同一模型有所变化,这可以通过根据结构相似性对最佳模型进行聚类来明确。在这种情况下,局部结构的优化和FEP参数的优化通常能够使模型收敛到一个适合前瞻性FEP使用的最优模型。
通常情况下,当多个模型显示出良好的RB-FEP准确性时,它们通常基于同一模型有所变化,这可以通过根据结构相似性对最佳模型进行聚类来明确。然而,如果现有的回顾性活性数据不足,那么可能会有多个差异显著的模型在该阶段显示出合理的RB-FEP预测结果。
通常情况下,当多个模型显示出良好的RB-FEP准确性时,它们通常基于同一模型有所变化,这可以通过根据结构相似性对最佳模型进行聚类来明确。在这种情况下,需要进一步测试最佳模型,以区分那些可用于前瞻预测的模型和潜在的假阳性结果(根据定义,这些假阳性结果在前瞻性预测中无法成立)。AB-FEP以及对RB-FEP验证数据集的扩展(可能包括同一系列中的非结合物)是区分顶级模型的典型方法。
(以上内容均由Ai生成)







