一种基于迁移学习的新型声学特征工程,用于场景假音频检测
快速阅读: 据《Nature.com》称,本研究提出了一种新的迁移学习方法MfC-RF(MFCC-随机森林),用于伪造音频检测。该方法基于SceneFake数据集,提取梅尔频率倒谱系数(MFCC)并进行分类预测。实验结果显示,MfC-RF方法达到了0.98的高精度,优于现有技术。研究提升了识别被操纵音频内容的准确性和效率,有助于增强数字通信的安全性。
Translation:
本研究提出了一种新的迁移学习方法MfC-RF(MFCC-随机森林),用于伪造音频检测。该方法基于SceneFake数据集,提取梅尔频率倒谱系数(MFCC)并进行分类预测。实验结果显示,MfC-RF方法达到了0.98的高精度,优于现有技术。研究提升了识别被操纵音频内容的准确性和效率,有助于增强数字通信的安全性。
音频取证在法律和安全目的的录音调查和分析中扮演着重要角色。使用语音结合场景操纵音频的音频伪造攻击手段代表了伪造音频检测中的一个复杂挑战。伪造音频检测,作为现代数字安全的关键技术,应对着各应用领域中日益增长的被操纵音频内容威胁。使用语音结合场景操纵音频的音频伪造攻击手段代表了伪造音频检测中的一个复杂挑战。
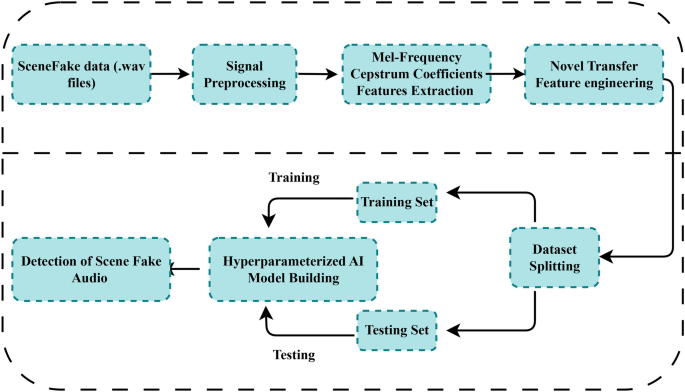
本研究提出了一种新的迁移学习方法用于伪造音频检测。我们利用了一个基准数据集SceneFake,其中包含12,668个真实和伪造场景的音频信号文件。我们提出了新提出的MfC-RF(MFCC-随机森林)方法,该方法首先提取梅尔频率倒谱系数(MFCC),然后进行分类预测的概率值特征。由新提出的MfC-RF(MFCC-随机森林)方法生成的迁移特征集用于进一步实验。结果显示,采用MfC-RF特征的随机森林方法达到了0.98的高精度,优于现有的最先进方法。我们对应用的机器学习方法进行了超参数调优,并通过交叉验证验证性能。此外,还评估了计算复杂性。
本研究旨在提升识别被操纵音频内容的准确性和效率,从而有助于数字通信的完整性和可靠性。
(以上内容均由Ai生成)







