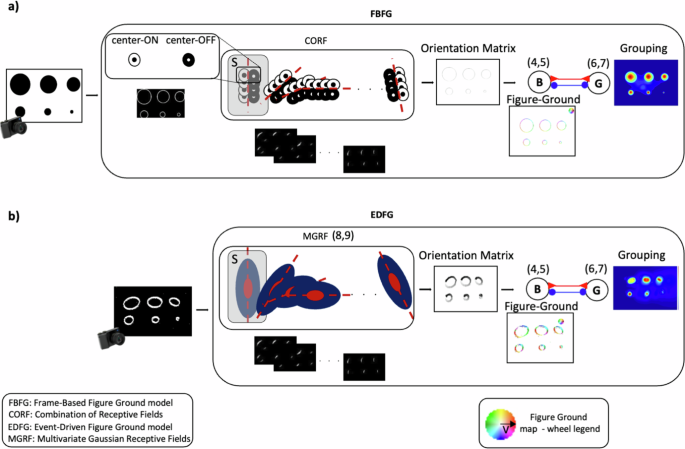
人形机器人 iCub 的事件驱动图形-地面组织模型
快速阅读: 《Nature.com》消息,图5展示了不同模型在分割复杂场景时的表现,如图像#8143所示,基于帧和基于事件的方法都无法正确分离对象。图像#134008显示基于事件的方法在复杂图案中表现更好。图6通过结构相似性和均方误差评估了模型与真实情况的接近程度,结果显示两种模型与真实情况相似,但基于事件的方法略有不足。
随后,在图5中可以看到真实分割图的角度信息与基于帧和基于事件的前景背景图的角度信息对比。所选图像展示了最佳结果(#135069、#105019和#118035,图5中的绿色边框)和最差结果(#8143,图5中的红色边框)。特殊情况下,图像#8143展示了一个复杂的杂乱场景,在此场景中,基于帧(FB)和基于事件(ED)的角度图无法正确分离对象。
在图像#134008中(图5中的蓝色边框),只有基于帧的前景背景(FBFG)未能在复杂图案前景中找到任何边缘,而基于事件的前景背景(EDFG)由于对比度变化生成事件的特点,能够清晰检测到该图案。图像#12003和#134008(图5中的蓝色边框)展示了人类能够正确标记整个星形为前景,而两种模型缺乏更高层次的认知机制来感知性地将这些图案组合成整个物体。由于模型的工作范围,基于帧和基于事件的模型将星形中的每个小物品分割为原型对象。
图6展示了基于事件的前景背景模型与基于帧的实现之间的比较,以及两种模型与真实情况之间的比较,计算了角度图与真实情况之间的结构相似性(SSIM)和均方误差(MSE)。图6中的SSIM比较结果显示,基于帧和基于事件的实现与真实情况的结果相似,而MSE略高。
此外,不同于MSE结果中观察到的变化,由于SSIM对相似性的整体评估,三种比较中SSIM结果无显著差异。SSIM使用标准Matlab库进行计算,默认窗口大小为11×11像素。这有助于评估基于事件的实现与原始基于帧的实现的一致性,并评估两种模型与真实情况的接近程度。
(以上内容均由Ai生成)







