使用人工智能方法在古兰经翻译中保留情感:在著名的古兰经英文翻译中学习
快速阅读: 《Nature.com》消息,本文综述了翻译中情感保留的相关文献,分为《古兰经》翻译和机器翻译两个研究方向。前者探讨了翻译连贯性和文化差异带来的挑战,后者研究了机器翻译在情感保留方面的缺陷及改进方法。本文弥补了先前研究的不足,引入了AI和ML技术,全面分析情感保留问题。
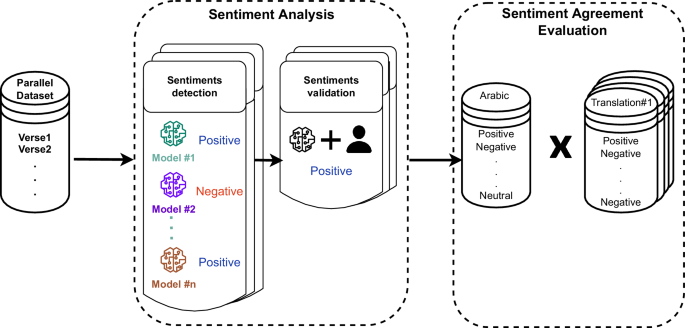
翻译过程必须确保领域知识从源语言到目标语言的保存和维护。然而,最近的研究表明,许多翻译经常未能保留源语言中固有的重要信息(Kumari等,2021)。因此,系统保持情感类别(即情感保留)的能力至关重要。本文从不同角度探讨了与翻译中的情感保留问题相关的文献,大致分为两条主要研究路线。一方面,如前所述,一些文献揭示了《古兰经》翻译的问题。这一研究路线与当前工作最为接近。例如,Farghal和Bloushi(Farghal和Bloushi,2012)证明,《古兰经》翻译中的连贯性变化导致了显著影响文本意义的不匹配。源语言和目标语言受众之间的文化差异可能导致某些不匹配是读者导向的连贯性变化。相反,其他不匹配可能源于译者的判断失误,并表现为文本导向的连贯性改变。研究表明,读者导向的调整给译者带来了困难,脚注和释义被证明是最有效的填补部分或完全文化/参考差距的方法。这种解释方法帮助《古兰经》译者避免危及《古兰经》的意义。同样,Rezvani和Nouraey(Rezvani和Nouraey,2014)基于Catford(Catford,1965)的转换类型理论进行比较分析,调查了从阿拉伯语翻译成英语的《古兰经》中各种转换的发生频率。这导致选择了七个翻译版本——Sarwar、Arberry(Arberry,1996)、Irving(Irving,1992)、Pickthall(Pickthall等,1960)、Saffarzade(Saffarzade,2001)、Shakir(Shakir,1985)和Yusef Ali(Ali,2000)——对《古兰经》中“约瑟夫”章的前三十节进行考察。首先比较了每个组成部分以寻找潜在的转换。然后使用卡方检验确定转换频率是否存在统计学上的显著差异。根据他们的研究结果,五种不同的变化在统计上显示出显著差异。Abdelaal(Abdelaal,2019)也指出了《古兰经》中几节经文翻译过程中遇到的困难及其解决方法,考虑了各种理论和实践观点。为此,特意选择了两章中的六节经文进行研究。随后发现Pickthall、Abdel Haleem(Haleem,2005)和Sarwar的翻译存在多个问题并丧失了意义。此外,Tabrizi和Mahmud(Tabrizi和Mahmud,2013)在比较《古兰经》的阿拉伯文原文和英文翻译时,探讨了话语结构问题。他们从实体连贯性和词汇衔接的角度,考虑句子、短语和词语排列的变化,调查现有翻译的《古兰经》等效性和准确性。另一方面,越来越多的文献研究了机器翻译在情感保留方面的缺陷(AR等,2013;Barhoumi等,2018;Pal等,2014;Shalunts等,2016;Wan等,2022;Zhang和Matsumoto,2019),或者研究了有效分析阿拉伯语情感的方法(Alqahtani等,2023;Farha和Magdy,2021;Sherif等,2023;Yu等,2023)。机器翻译中如何保留情感的问题被作为二元或三元分类问题来研究。例如,Lohar等(Lohar等,2017)构建了一个情感分类器,研究情感保留和翻译质量,假设当翻译质量低时,情感可能无法得到适当保留。研究发现,将情感类别纳入机器翻译系统的训练数据可以提高目标语言的情感保留。此外,Lohar(Lohar,2020)在用户推文中研究了机器翻译质量和情感保留的质量,特别关注情感分类是否有助于情感保留。主要是通过基于情感分类的机器翻译模型来提高推文的机器翻译质量,同时保持情感极性。同样,Saadany和Orasan(Saadany和Orasan,2020)分析了从阿拉伯语翻译成英语的书评翻译难题,重点是导致情感极性错误翻译的错误。它强调了阿拉伯语用户生成内容(UGC)的独特性质,调查了翻译阿拉伯语UGC到英语时的情感转移错误,并探讨了问题产生的原因。研究表明,机器翻译技术对于阿拉伯语UGC的输出要么完全反转目标词或短语的情感极性,提供错误的情感信息,要么根本不传达情感,而是提供中性的目标文本。同样,Saadany等(Saadany等,2021)提出了一种方法,确定自动翻译技术能否成功传达UGC中的情感。他们发现存在一些独特的语言特性,使得情感难以翻译成其他语言。描述了这些特性的最佳总结以及它们在不同语言组合中出现的频率。Kumari等(Kumari等,2021)和Si等(Si等,2019)则采取了略有不同的路径。例如,Kumari等提供了一种深度强化学习方法,用于微调神经机器翻译系统的参数,使最终翻译能够正确编码潜在的情感。他们在英语-印地语和法语-英语的不同领域评论数据集上分析了所用的技术,发现该技术在情感分类和机器翻译任务上比监督基线有显著改进。尽管上述研究阐明了《古兰经》翻译和机器翻译问题,特别是在情感保留方面,但仍有一些空白需要填补。首先,之前关于《古兰经》的研究没有利用AI和ML技术,更不用说TLMs,而是依赖于手动定性分析。其次,由于依赖手动定性分析,通常只选择和分析有限数量的样本(《古兰经》的经文),而不是整个《古兰经》。第三,之前研究的重点仅在于语义传递,而非情感保留。第四,即使有关于使用ML分类方法研究机器翻译问题的研究,也没有采用TLMs,尽管它们在各种AI、ML和NLP任务中表现出色。这些空白都在本文的工作中得到了解决。
(以上内容均由Ai生成)







