Sesame AI 开源对话语音模型的快速演示
快速阅读: 据《药物发现与开发》最新报道,芝麻AI开源的会话语音模型CSM能生成逼真音频,尤其擅长短音频片段。尽管需一定技术基础,但它轻量化且自然度优于许多现有语音生成器。CSM的开源有助于打破语音技术垄断,推动其普及与创新应用,但其实际场景和质量仍有提升空间。
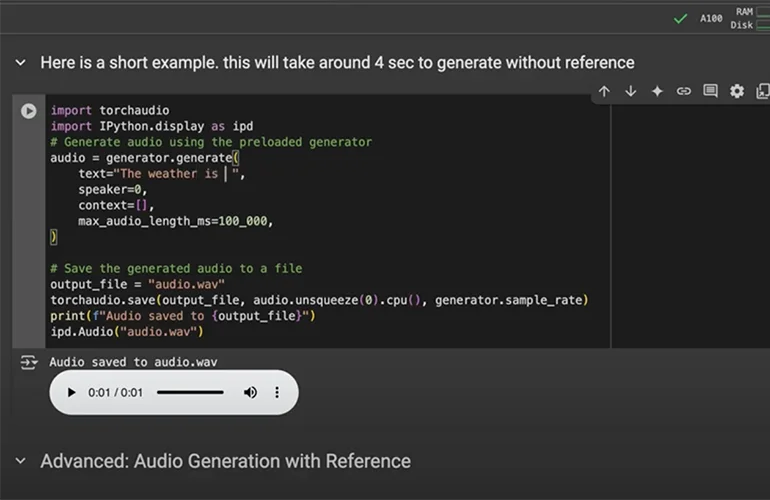
芝麻AI近期开源了其会话语音模型(CSM),这款工具能够利用训练数据或自定义声音生成逼真的音频。需要注意的是,该模型在较短的音频片段上表现尤为突出,例如单句而非长篇段落。同时,它并不适合直接进行自然对话。观看我的演示后会发现,设置过程并非即插即用。你需要一个Hugging Face账户、一块性能良好的GPU以及一定的Python编程基础。不过,一旦一切准备就绪,成果便显而易见。虽然首个演示听起来略显机械化,但后续的语音样本显得更为自然,不再是我们习惯于从Siri和Alexa等虚拟助手那里听到的单调机械音。对我来说,开源的CSM甚至听起来比OpenAI的高级语音模式还要优秀。然而,当系统接收到合适的参考录音时,它的优势才得以真正展现。我从Mozilla的Common Voice数据集中获取了一些样本,发现输入声音与输出之间的相似性令人印象深刻。当转录内容与参考音频中的内容完全匹配时,该模型能够高效地克隆语音特征。这无疑引发了伦理问题。芝麻明确禁止将CSM用于模仿或制造误导性内容。其使用条款禁止模仿、欺诈、虚假信息、欺骗、非法或有害活动。尽管如此,我还是对由此造成的潜在伤害感到担忧。你只需要一段某人说话的MP3录音,就可以生成他们未曾说过的新话语。
从实际应用来看,CSM处于一个有趣的中间地带。它仅包含10亿参数,因此轻量化到可以在现代中端游戏GPU上运行。在我的测试中,我使用了A100。正如前面提到的,一个权衡在于上下文长度的限制。别指望用它来生成初学者使用的电子显微镜使用指南。CSM最适合处理简洁的短语和句子。由于CSM不具备对话能力,如果你想构建交互式系统,就需要将其与LLM结合使用。Python API足够简单,经验丰富的开发人员应该不会觉得连接这些组件有太大挑战,但我不属于这一类开发者,因此无法评论CSM的定制实现。
从研发角度来看,CSM的发布意义重大,因为它是一个开源发布。因此,这是打破语音技术领域垄断壁垒的重要一步。想想看——第一代语音助手如Siri和Alexa都是完全封闭的生态系统。语音即是产品、品牌和体验,而这些都是由苹果、亚马逊和其他大型科技公司精心控制的。芝麻AI实际上正在让高质量的语音合成走向普及,可能会激发新一轮关于语音AI情感乃至讽刺识别的研究热潮。那些无力打造专属语音系统的中小型企业及独立开发者现在可以将自然语音融入他们的产品中。我们很快将在意想不到之处见到语音界面的身影——新的汽车、下一代物联网设备,超越简单的天气预报和计时功能,提供更丰富、更复杂的互动体验。下一轮语音界面似乎不太可能由科技巨头定义,而是由多样化开发者生态系统的创新实践推动。
所以,我对这个演示的评价是?让我们给个8/10吧。它的开箱即用应用场景尚不明晰,质量也有点不稳定。但CSM听起来比许多其他AI语音生成器要好得多,那些生成器多年来一直有着单调的语调。是时候出现一些新东西了。
(以上内容均由Ai生成)







