超算存储面临挑战,VDURA提出解决方案
快速阅读: 超级计算机领域正经历重大变革,英伟达凭借GPU技术引领行业发展,推动高性能计算向AI转型。传统存储系统难以应对AI的高I/O需求,新兴的并行文件系统和高性能存储方案应运而生,成为关键竞争力。
超级计算机领域正在分裂。曾经相对统一的大规模多处理器x86系统世界,现在分化为多种竞争架构,各自竞相服务于截然不同的需求:传统的学术工作负载、极端规模的物理模拟以及AI训练的巨大需求。
在这场变革的核心,英伟达(Nvidia)凭借其GPU革命不仅取得了突破,更是彻底颠覆了旧有秩序。
后果显著。支持数十年科学突破的传统存储系统,在AI的持续随机I/O风暴下不堪重负。原本设计用于顺序吞吐量的设施,现在面临新的现实,其中元数据可能占所有I/O操作的20%。随着GPU集群扩展到数千节点,一个残酷的经济真相浮现:每一秒的GPU空闲时间都会造成资金流失,这使得存储从辅助功能转变为决定性的竞争优势。
我们与VDURA公司的首席执行官肯·克拉菲(Ken Claffey)进行了交谈,以了解这一根本性转变如何迫使超级计算基础设施从硬件到软件、从架构到经济的全面重新思考。
《区块与文件》:如何定义超级计算机和高性能计算(HPC)系统?它们之间有何区别?
肯·克拉菲:界限确实模糊且越来越不明显。历史上,这种划分主要基于系统的规模(节点数量)。随着基于Linux的商用服务器集群成为默认构建模块(而非早期的Cray定制超级计算机或NEC矢量超级计算机),传统的工作组、部门、分部和超级计算机的分类可能需要更新。如今,即使是小型GPU集群的价值也足以被分析师归类为超级计算机销售。
《区块与文件》:有哪些不同类型的超级计算机,它们是否因工作负载和处理器而异?
肯·克拉菲:并非所有超级计算机都相同。有Linux集群超级计算机,这些在当前的Top500榜单中占据主导地位。它们由数千台通过InfiniBand、以太网或专有互连连接的商用服务器构建而成。变体包括:
– 大规模并行集群,具有分布式内存(例如,能源部的Frontier)。每个节点运行自己的操作系统并通过消息传递进行通信。
– 由现成的x86/GPU服务器构建的商品集群;超大规模AI集群属于此类。
– 不同的工作负载偏好不同的架构,如CPU密集型、GPU密集型或内存中心型。天气和物理模拟受益于低延迟互连的矢量或大规模并行集群。
– 现代AI训练通常使用GPU密集型商品集群。
– 特殊用途系统服务于狭窄领域,如密码学或模式匹配,但在AI相关应用场景中,特别是推理方面,它们再次获得关注,例如Grok、SambaNova等。
《区块与文件》:英伟达的NVL72机架级GPU服务器算不算超级计算机?
肯·克拉菲:英伟达将其GB200 NVL72描述为“机架内的exascale AI超级计算机”。每个NVL72包含18个计算托盘(72个Blackwell GPU与Grace CPU配对),通过第五代NVLink交换机连接,提供130 TBps的互连带宽。NVLink结构创建了一个统一的内存域,总带宽超过每秒1 PB,单个NVL72机架可提供80 petaflops的AI性能和1.7 TB的统一HBM内存。
从纯粹的HPC角度来看,单个NVL72更像是一个机架级构建模块,而不是完整的超级计算机,因为它缺乏外部存储和集群管理层,这些是全面HPC所必需的。但是,当数十或数百个NVL72机架与高性能存储(如VDURA V5000)互联时,所得系统无疑可以称为超级计算机。因此,NVL72位于边界上:一个极其密集的GPU集群,可以成为更大HPC系统的一部分。
《区块与文件》:您认为英伟达的GPU HBM能否转移到其他类型的超级计算机?为什么英伟达开发了HBM,而其他超级计算机类型没有?
肯·克拉菲:高带宽内存(HBM)通过硅通孔堆叠DRAM芯片,提供千位宽接口;HBM3e每GPU可提供高达1.8 TB/s的速度。HBM并不独属于英伟达,AMD的MI300A/MI300X、英特尔的Ponte Vecchio及许多AI加速器都使用HBM,因为以每秒太字节速度流式传输数据对于满足饥饿的核心至关重要。HBM的采用取决于经济性和封装设计:GPU可以承受成本,因为它们提供非常高的每瓦浮点运算次数,而通用CPU通常依赖于带宽较低的DDR/LPDDR内存。
英伟达在GPU高带宽内存(HBM)领域的领导地位,得益于人工智能对内存带宽的无尽需求。GPU制造商与HBM供应商(如三星、美光、SK海力士)合作设计硅片,以最大化带宽。传统超级计算机厂商通常关注以CPU为中心的工作负载,在这些场景中,大容量DDR内存比原始带宽更重要。我们预计,HBM将在基于GPU的人工智能系统和某些CPU架构中普及,但商品服务器将继续在成本和容量之间寻求平衡,使用DDR内存。最终,内存技术将在经济合理的领域得到推广。
超级计算领域如何应对训练和推理等人工智能工作负载?
肯·克拉菲:
人工智能革命将高性能计算设施转变为AI工厂。从客户那里可以明显看出,他们的应用程序环境正在发生变化,随着用户越来越多地部署基于AI的应用程序,这给高性能计算基础设施带来了新的挑战,因为他们正在增加集群中的GPU数量。这反过来又影响了存储,因为AI应用程序以GPU为中心,产生尖锐、随机的I/O模式,导致元数据占I/O的10%到20%。无论是训练还是推理,都需要持续的吞吐量:英伟达建议DGX B200服务器每GPU需要0.5 GBps读取速度和0.25 GBps写入速度,视觉工作负载则高达每GPU 4 GBps。这意味着一个10,000个GPU的集群需要5 TBps的读取带宽和2.5 TBps的写入带宽。
为了满足这一需求,高性能计算中心正在采用并行文件系统和以NVMe为主的架构。AI训练仍然依赖于高吞吐量的并行文件系统来喂养GPU和处理大规模检查点,而推理工作负载则转向对象存储和键值语义,需要强大的元数据性能和多租户支持。随着GPU加速器的兴起,I/O模式从大型顺序写入转变为高度随机的小文件操作。因此:
– 高性能计算设施正在升级网络至InfiniBand NDR和400 Gb/s以太网,并部署基于NVMe的存储服务器以充分利用GPU。
– 厂商正在增加GPU Direct和基于RDMA的I/O路径,以绕过CPU瓶颈并减少延迟。
– AI和高性能计算团队越来越将数据管道视为生产线,强调弹性和自动化。VDURA的白皮书指出,GPU空闲时间和缓慢的检查点浪费资金,促使新的存储架构最小化停滞时间。
超级计算和高性能计算存储是如何演化的?主要趋势是什么?
肯·克拉菲:
高性能计算存储已经从专有、硬件绑定的架构发展到面向AI和GPU驱动工作负载的软件定义、横向扩展系统。此外,虽然高性能计算的设计概念是临时/Scratch高性能文件系统,但AI更加注重持续性能和广泛的SLA,更关心运营可靠性。
– 从专有到软件定义:早期高性能计算依赖于封闭系统,配备HA对和专用RAID控制器。现代平台已转向与超大规模设计对齐的SDS模型,采用无共享架构,水平扩展至包含NVMe节点的通用硬件和开放供应链。
– 闪存与HDD,而非仅闪存:从HDD到NVMe闪存的转变带来了巨大的性能提升,但规模效率现在取决于利用整个介质范围;SLC、TLC、QLC闪存和CMR/SMR HDD,以平衡吞吐量、IOPS耐久性和成本。
– 元数据和自动化:AI的数十亿小文件使得元数据成为潜在的性能瓶颈,且占存储数据的比例不断增加,约为10%到20%。VDURA的VeLO分布式元数据引擎消除了这一瓶颈,支持数十亿次操作,具有超低延迟。
– 规模下的运营可靠性和弹性:传统的节点本地RAID已被网络级纠删码取代,以提高对故障的弹性——提高耐用性和可用性。VDURA实际上提供了更多功能,其多级纠删码(MLEC)实现更高的可用性,达到12个9的耐用性,确保全年无休的连续运行。
– 高性能计算存储已演变为AI就绪、软件定义的基础设施;以闪存为主、介质感知、元数据加速、运营弹性足以跟上最快的GPU,实现全年无休的持续运行。
主要的超级计算机存储系统有哪些?它们有何不同?
肯·克拉菲:
超级计算机存储沿着一条明显的界限分化为传统的硬件绑定系统和现代的软件定义架构,后者针对AI和数据密集型工作负载构建。
– 传统系统:依赖于专有硬件,采用RAID技术和封闭架构,适用于过去的数据处理模式。
– 现代系统:采用软件定义存储(SDS),支持横向扩展,适应AI和大数据处理的需求,提供更高的灵活性和性能。例如,VDURA的解决方案通过分布式元数据管理和多级纠删码技术,实现了卓越的性能和可靠性。
行业正在从硬件定义的“系统”(如控制器对、专有阵列)转向软件定义存储(SDS)“平台”,这些平台运行在通用NVMe和HDD介质上。SDS促进了更快的创新,支持混合介质分级(SLC、TLC、QLC闪存+CMR/SMR硬盘)、元数据加速和云级可扩展性——这是VDURA架构的基础。
为什么有这么多不同的文件系统?它们是否适用于不同的超级计算工作负载?
Ken Claffey表示,尽管高性能计算(HPC)生态系统看似多样化,但只有少数几种文件系统在数千个环境中经过了生产规模的验证。其他许多仍处于研究项目或小众部署阶段。
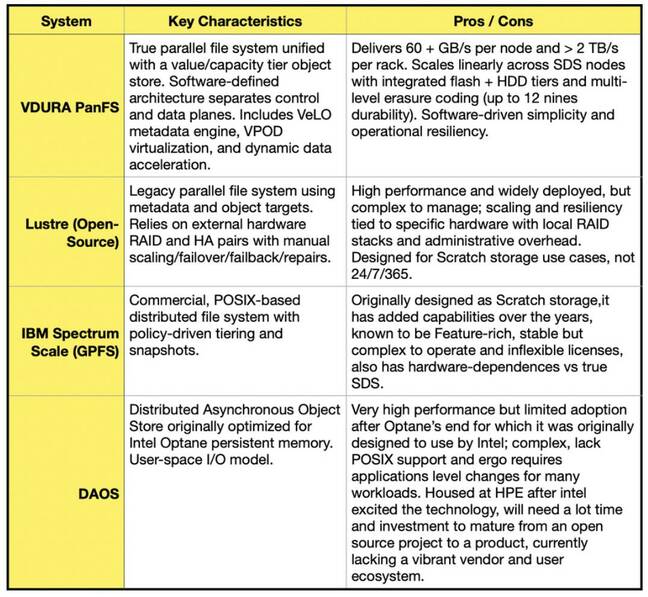
传统系统与软件定义平台:传统的HPC文件系统,如Lustre或GPFS,依赖于硬件绑定并手动扩展。现代并行文件系统,如VDURA的PanFS,代表了软件定义平台,分离了控制平面和数据平面,符合超大规模风格的无共享架构,并运行在通用NVMe和HDD供应链上。
项目与产品:开源努力(例如DAOS)推动了创新,但通常停留在项目级别,而商业SDS平台由于长期投资和持续开发,演变成了成熟的产品,平衡了性能、可管理性和长期支持。
工作负载适配:AI和HPC工作负载差异显著,有些需要流式传输多太字节的顺序数据,另一些则随机读取数十亿个小文件。没有一种文件系统可以优化所有情况,因此定制存储正在取代通用设计,如NAS和SAN系统。像VDURA这样的混合SDS平台集成了闪存和HDD层级,处理元数据加速,提供几乎无限的线性性能扩展,并满足当今AI工厂所需的可用性和持久性。
虽然HPC存储领域有许多名称,但只有少数真正能在生产环境中大规模操作,且明显趋势是从传统硬件系统向灵活、软件定义、定制化的数据平台转变。
为什么DAOS没有变得更流行?
Ken Claffey解释说,DAOS是一个开源项目,目前更多被视为技术集合而非成品。它现在由HPE托管,预计HPE将投入大量资源使其成为真正的成品,就像他在ClusterStor时对Lustre所做的那样。这将需要多年的重投资、大规模部署和运营成熟度,才能从“项目”转变为“产品”。
VDURA如何利用DAOS?PanFS能否发展到采用DAOS概念?
Ken Claffey认为,键值存储(KVS)元数据方法的方向是正确的,与PanFS长期以来的操作方式非常相似。这一概念现在也体现在VDURA数据平台上,我们在其中进一步推进和发展了元数据引擎,以满足现代AI和HPC工作负载的需求。
为什么吞吐量对AI工作负载很重要?
Ken Claffey指出,IOPS(每秒输入/输出操作次数)衡量存储系统可以执行多少4 KiB的小操作,这对于事务数据库和虚拟机来说是个不错的指标。然而,AI和HPC工作负载涉及大数据集和检查点的流式传输。关注IOPS可能会产生误导,因为AI工作负载是由吞吐量驱动的,以GBps或TBps为单位测量,因为它移动的是大容量的顺序数据集。高带宽确保GPU保持忙碌状态,防止训练过程中因检查点而停滞。并行文件系统通过在多个节点之间分配数据来提供这种聚合带宽。如果没有足够的吞吐量,GPU会饥饿,昂贵的计算周期就会被浪费。VDURA的V5000系统每个节点可提供超过60 GBps的吞吐量,每个机架可提供超过2 TBps的吞吐量。这确保AI管道的限制因素是模型复杂度,而不是存储。VDURA还提供每个机架高达1亿次IOPS的能力,因此也能处理元数据密集型推理工作负载。结论是,吞吐量和IOPS都很重要,但对于AI训练而言,吞吐量是关键。
并行存储系统是否为超级计算机带来了非并行(串行)存储系统无法提供的特定优势?
Ken Claffey肯定地回答,非并行NAS系统,如NetApp ONTAP,依赖少量控制器处理I/O。正如他之前所指出的,通用NAS无法提供AI所需的数据吞吐量或可靠性。NetApp的AFX是他们尝试构建的并行文件系统。主流存储系统最初是为了通用计算而设计的。
NetApp已经承认,为了应对AI领域的先进计算,他们需要一种新的产品,即并行文件系统。他们没有准备好迎接未来,现在正在努力追赶。
Nvidia与Oracle合作为能源部建造7台超级计算机,其中包括其最大的一台。
Nvidia的DGX Spark,最小的超级计算机,以稳健的速度处理大型模型。
AI不仅没有阻碍HPC,反而就是HPC。
NextSilicon Maverick-2 承诺将冲击 Nvidia 留下的高性能计算市场。Blocks & Files 询问:GPU Direct 是否能使非并行存储系统(如 NetApp)实现并行效果?Ken Claffey 回答说,这不可能。如果系统不是并行的,其速度受限于单个路径的速度。尽管 GPU Direct 可以加速这条路径,但这并不如多路径并行文件系统那样可扩展,尤其是在这些路径也支持 GPU Direct 的情况下。当被问及 VDURA 的 PanFS 支持 GPU Direct 后,VDURA 如何进一步适应 Nvidia GPU 服务器的需求,例如通过 KV Cache 卸载时,Claffey 表示他们正在研究相关领域,敬请期待。®
赞助商:在 Google Cloud 上免费开始使用生成式 AI。分享
更多关于
超级计算机
类似文章
×
更多关于
超级计算机
细分主题
超级计算
广泛主题
计算机
提供线索
向我们发送新闻
(以上内容均由Ai生成)