美团LongCat推出UNO-Bench,全面提升多模态模型评估能力
发布时间:2025年11月6日
来源:szf
快速阅读: 美团LongCat团队推出UNO-Bench基准测试,涵盖44种任务类型和5种模态组合,数据集跨模态可解性达98%,运行速度提升90%,并引入多步骤开放式问题评估模型复杂推理能力。
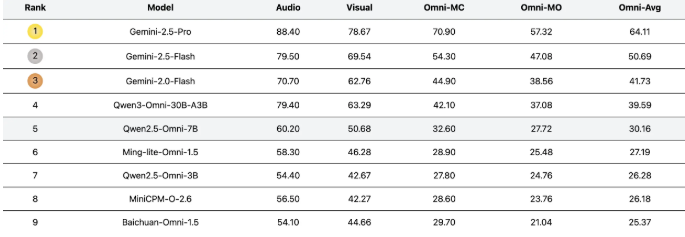
近日,美团LongCat团队推出名为UNO-Bench的新基准测试,旨在系统评估各类模型在不同模态下的理解能力。该基准测试涵盖44种任务类型和5种模态组合,力求全面展示模型在单模态与全模态下的性能。
UNO-Bench的核心优势在于其丰富且高质量的数据集。团队精选了1250个全模态样本,这些样本的跨模态可解性达到98%。此外,还加入了2480个增强的单模态样本,这些样本充分考虑了实际应用场景,尤其在中文环境中表现出色。值得注意的是,经过自动压缩处理后,数据集的运行速度提升了90%,并在18个公开基准测试中保持了98%的一致性。
为了更好地评估模型的复杂推理能力,UNO-Bench引入了一种创新的多步骤开放式问题形式。该形式结合通用评分模型,能够自动评估六种不同题型,准确率达到95%。这一创新评估方式为多模态模型的评测提供了新思路。
目前,UNO-Bench主要关注中文场景,团队正积极寻找合作伙伴,计划共同开发英语及其他多语言版本。感兴趣的开发者可通过Hugging Face平台下载UNO-Bench数据集,相关代码和项目文档已在GitHub上公开。
随着UNO-Bench的发布,多模态大语言模型的评估标准将进一步提升,不仅为研究人员提供有力工具,也为整个行业的发展铺平了道路。项目地址:https://meituan-longcat.github.io/UNO-Bench/
(以上内容均由Ai生成)