Perplexity优化AI模型,实现老旧硬件上高效运行
快速阅读: Perplexity开发新技术,使大型AI模型能在低成本旧硬件上高效运行,解决内存和网络延迟问题,尤其优化了亚马逊EFA的性能,提升多节点配置下的模型推理效率。
AI搜索提供商Perplexity的研究团队开发了一套新的软件优化技术,使得大型模型(参数量达到万亿级)能够通过现有的多种网络技术,包括亚马逊专有的弹性结构适配器(Elastic Fabric Adapter, EFA),在老旧且成本较低的硬件上高效运行。
这些创新成果本周以论文形式发表,并在GitHub上公开,供进一步审查。它们提供了一种新颖的方法来解决大规模专家混合模型(Mixture of Experts, MoE)部署时面临的主要挑战之一:内存和网络延迟问题。
MoE模型,如DeepSeek V3和R1或Moonshot AI的Kimi K2,规模庞大,参数量从6710亿到1万亿不等。这意味着,这些模型无法在配备旧H100或H200 GPU的八GPU系统上大规模运行。虽然有时可以加载模型权重,但剩余的内存不足以支持关键值缓存(即模型的短期记忆),这限制了其服务规模。
要解决这一问题,要么需要更大的系统,要么将模型分片部署在多个较小的系统上。理想的选择是使用Nvidia的GB200或GB300 NVL72机架系统,该系统相当于一个大型服务器,配备72个192GB或288GB的GPU,足以支持更大规模的多万亿参数LLM模型。然而,这些系统的成本高昂,需求极大,且可能无法在所有地区获得,尤其是中国。相比之下,旧的H100或H200系统较为丰富且相对便宜,但需要将模型分布在多个节点上,这通常会导致性能显著下降。
这种性能下降在从密集模型转向稀疏MoE模型时更为明显。在密集模型中,每次生成一个标记(如单词片段或标点符号)时,都会从内存中读取整个权重。而在稀疏MoE模型中,请求被路由到一组较小的权重,称为专家。每个标记可能由不同的专家组生成,这虽然减少了实现预期交互水平所需的内存带宽,但从网络通信的角度来看,却变得更加频繁。
对于单节点或机架系统,高速互连如NVLink或AMD的Infinity Fabric可以轻松应对额外的流量。但对于分布在多个节点上的模型,不同系统的GPU之间可能通过速度慢7到14倍的互连通信,这增加了复杂性。
为了解决这个问题,DeepSeek V3背后的开发者开发了DeepEP框架,旨在最小化其模型在多个H800系统上运行时的性能损失,这些系统通过Nvidia的ConnectX网卡连接。
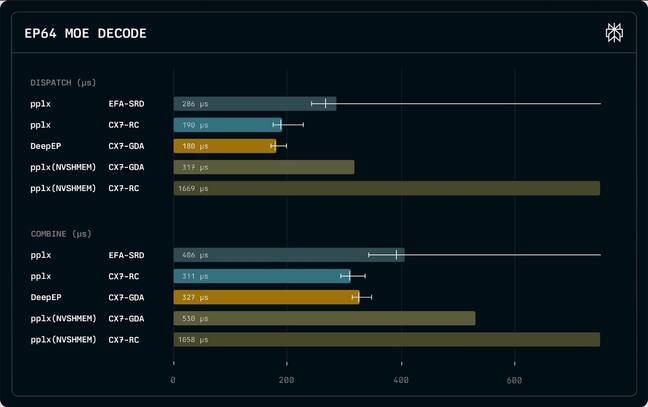
然而,并不是所有人都在计算环境中使用Nvidia的网卡。例如,亚马逊网络服务(AWS)使用的是自己开发的网络协议——弹性结构适配器(EFA)。EFA支持高达400Gbps的聚合带宽,但在MoE调度和组合过程中交换的消息大小方面不如Nvidia的网卡表现好。此外,EFA不支持GPUDirect Async技术,这项技术允许网卡绕过主机CPU直接与GPU通信,因此在某些工作负载下,EFA会因数据需先通过CPU代理而产生延迟。
为了解决这些问题,Perplexity开发了一套新的内核——优化后的软件例程,用于处理GPU之间的通信。该公司声称,这套内核在Nvidia的ConnectX-7网卡上实现了比DeepSeek的DeepEP更低的延迟,并使得使用EFA进行MoE模型的分布式推理成为可能。
与DeepSeek现有的DeepEP库相比,Perplexity的内核在某些指标上表现略优,尤其是在Nvidia的ConnectX-7上运行时,同时还将EFA的延迟降至可接受的水平。为了验证这些测试结果,Perplexity在其内部推理引擎上使用EFA进行节点间通信,测试了这些内核在一系列AWS H200 p5en实例上运行DeepSeek V3和Kimi K2的情况。
虽然DeepSeek V3并非万亿参数模型,其参数量接近7000亿,但体积足够小,能够部署在单个H200实例上,因此可以作为评估性能提升的基准。
在测试中,Perplexity将单个八GPU系统的性能与16个GPU(两个实例)或多至32个GPU(四个实例)的多实例设置进行了对比。尽管在低批量和高批量处理时性能相对稳定,但在中等批量处理时,多节点配置中的更高程度的专家并行性带来了更高的性能。
与单节点基线相比,Perplexity优化的内核在将模型分布在两个和四个节点配置上时,提供了显著的性能提升。
这些性能特征同样适用于更大的模型,如无法在单个实例上运行的Kimi K2。尽管带宽受限于Nvidia的NVLink或AMD的Infinity Fabric,后者比以太网快14倍以上,Perplexity仍然能够在多节点推理的中等批量处理中展示出有意义的性能提升。
对于拥有1万亿参数的更大规模Kimi K2模型,Perplexity优化的EFA内核在中等批量处理时也显示出性能提升。
Perplexity正持续优化其针对亚马逊EFA网络技术的内核。该公司表示,它正在跟踪亚马逊libfabric库的更新,以减少数据平面开销,并计划试验efa-direct以进一步降低延迟并提高整体性能。
然而,真正的受益者可能是那些能够更长时间利用现有硬件,或利用全球最大的云服务提供商提供的折扣实例类型,而不错过下一代前沿模型的用户。®
赞助:Google Cloud上的生成式AI。免费开始使用。
(以上内容均由Ai生成)







