Pangram 在 AI 文本检测中表现卓越,假阳性假阴性率几乎为零
快速阅读: 芝加哥大学研究显示,Pangram在AI文本检测中表现优异,FPR和FNR低至0.01以下,尤其在中长文本上几乎无误。相比,OriginalityAI和GPTZero在短文本检测中效果较差。Pangram的识别成本较低,研究呼吁定期审计以应对未来挑战。
最近,芝加哥大学的一项研究揭示了市场上各种商业AI文本检测工具之间的显著差异。研究团队构建了一个包含1992篇由人类撰写的文本数据集,涵盖亚马逊产品评论、博客文章、新闻报道、小说摘录、餐厅评论和简历等六类文本。同时,他们利用了四种领先的语言模型——GPT-41、Claude Opus4、Claude Sonnet4和Gemini2.0Flash,生成了相应的AI写作样本。
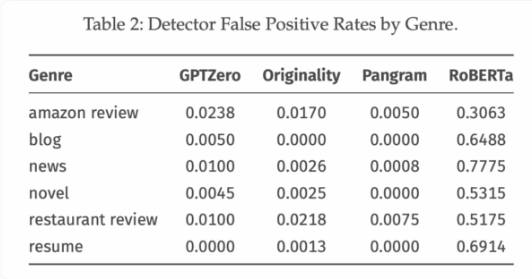
为了评估这些检测工具的性能,研究团队主要关注两个指标:假阳性率(FPR)和假阴性率(FNR)。FPR用于衡量人类文本被误标为AI生成的频率,而FNR则反映AI文本未被检测出的比例。在这次对比中,商业检测工具Pangram表现出色。对于中长文本,Pangram的FPR和FNR接近于零;在短文本方面,其错误率也普遍低于0.01,只有Gemini2.0Flash在餐厅评论中的FNR为0.02。
其他检测工具如OriginalityAI和GPTZero的表现略逊一筹,尽管在较长文本上的FPR保持在0.01以下,但在极短文本方面的表现不尽理想。此外,这些工具对“人性化”工具生成的AI文本也较为敏感。
Pangram在识别AI生成文本方面表现出色,所有四种模型生成的文本FNR均未超过0.02。相比之下,OriginalityAI的表现受生成模型的影响较大,而GPTZero在不同模型上的表现较为稳定,但依然不及Pangram。
研究团队还测试了各检测工具对StealthGPT工具的抵抗能力,该工具能够使AI生成的文本更难以被检测。Pangram在这些测试中表现稳健,而其他检测工具则面临较大挑战。
从经济效益来看,Pangram的平均识别成本为每正确识别一条AI文本0.0228美元,大约是OriginalityAI的一半和GPTZero的三分之一。研究提出了“政策上限”的概念,允许用户设定最大可接受的假阳性率,以更好地调整检测工具的使用。
研究团队警告称,这些结果仅反映了当前的情况,未来可能会在检测工具、新AI模型和规避工具之间上演一场“军备竞赛”。他们建议定期进行透明的审计,以适应这一快速发展的领域。
(以上内容均由Ai生成)







