蚂蚁百灵开源新模型,大幅提升长文本编程效率
快速阅读: 蚂蚁集团发布Ring-flash-linear-2.0-128K模型,采用混合线性注意力机制和稀疏MoE架构,仅激活6.1B参数实现高性能,支持128K上下文,提升长文本处理效率,助力高效AI编程。
在当前AI大模型竞争激烈的背景下,高效推理与长上下文处理成为开发者的痛点。近日,蚂蚁集团旗下的百灵大模型团队正式开源了Ring-flash-linear-2.0-128K,这是一款专为超长文本编程设计的创新模型。该模型以混合线性注意力机制和稀疏MoE架构为核心,仅需激活6.1B参数即可达到与40B密集模型相当的性能,在代码生成、智能代理等领域表现出色。AIbase基于Hugging Face官方发布和技术报告,独家解析了其突破性亮点,助力开发者进入“高效AI编程”新时代。
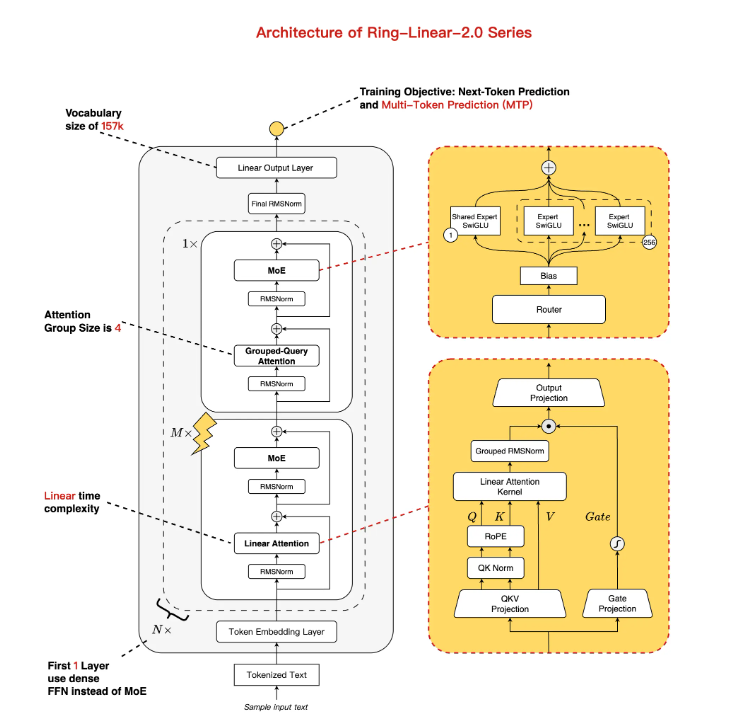
创新架构:线性与标准注意力混合,MoE优化平衡性能与效率。Ring-flash-linear-2.0-128K在Ling-flash-base-2.0基础上迭代升级,虽然总参数规模达104B,但通过1/32的专家激活率和多任务处理层(MTP)等优化措施,实际激活参数仅为6.1B(不含嵌入层4.8B),实现了近似线性的时间复杂度和常量空间复杂度。其核心亮点在于混合注意力机制:主干部分采用自主研发的线性注意力融合模块,辅以少量标准注意力,专门针对长序列计算提高效率。相较于传统模型,该架构在H20硬件上支持128K上下文下的200+ token/s生成速度,日常使用速度提升了3倍以上,特别适合资源受限的场景。
训练升级:1T令牌额外微调+RL稳定,复杂推理能力达到SOTA水平。该模型由Ling-flash-base-2.0转换而来,并在额外1T令牌的高质量数据集上进行了训练,结合稳定的监督微调(SFT)和多阶段强化学习(RL),解决了MoE长链推理训练不稳定的难题。得益于蚂蚁自主研发的“棒冰(icepop)”算法,该模型在高难度任务中表现出卓越的稳定性:在AIME2025数学竞赛中获得86.98分,CodeForces编程Elo评分达90.23,逻辑推理与创意写作v3方面超越了40B以下的密集模型(如Qwen3-32B)。基准测试显示,它不仅能够匹敌标准注意力模型(如Ring-flash-2.0),还在多项开源MoE/Dense模型中处于领先地位。
长上下文技术:原生128K+YaRN扩展至512K,长输入输出流畅无阻。针对编程中的痛点,Ring-flash-linear-2.0-128K原生支持128K上下文窗口,开发者可以通过YaRN外推技术轻松扩展至512K。在长形式输入/输出场景中,预填充(Prefill)阶段的吞吐量比Qwen3-32B提高了近5倍,解码(Decode)阶段更是达到了10倍的加速效果。实际测试表明,该模型在处理32K+上下文的编程任务时,能保持高精度,没有“穿模”或漂浮感的问题,特别适合前端开发、结构化代码生成和代理模拟等复杂场景。
开源即用:Hugging Face与ModelScope双平台部署,零门槛上手指南。为了加速社区落地,百灵团队已经将模型权重同步开源至Hugging Face与ModelScope,支持BF16/FP8格式。安装依赖后,用户可以通过Transformers、SGLang或vLLM框架一键加载。例如,Hugging Face示例命令为:pip install flash-linear-attention==0.3.2 transformers==4.56.1,加载后可以直接生成长代码提示。vLLM在线推理方面,在tensor-parallel-size为4的情况下,GPU利用率可达90%,并支持API调用。技术报告详见arXiv (https://arxiv.org/abs/2510.19338),开发者可以立即下载体验。
MoE线性注意力时代来临,蚂蚁百灵引领高效编程AI发展。此次开源标志着蚂蚁百灵在“MoE+长思维链+RL”技术路线上的新突破,从Ling2.0系列到Ring-linear,效率提升了7倍以上。AIbase认为,在成本仅为1/10的长文本推理浪潮中,该模型将重塑开发者生态系统:编程新手可以快速生成复杂的脚本,代理系统更加智能,企业级应用的部署也变得简单易行。未来,随着Ring-1T万亿级旗舰模型的推出,国产MoE有望在全球高效AI赛道上占据主导地位。
结语:Ring-flash-linear-2.0-128K以“小激活大性能”诠释了AI开源的新范式,为超长编程提供了强大的动力。开发者们,快来Hugging Face/ModelScope体验吧!AIbase将持续关注其社区迭代动态。
(以上内容均由Ai生成)







