Anthropic发布Claude Sonnet 4.5,强化编码能力

快速阅读: Anthropic 发布 Claude Sonnet 4.5,引入检查点、代码执行、文件创建等功能,提升代理能力,增强安全性,获业内好评。
Claude Sonnet 4.5 于今日发布,带来了多项编码改进,包括检查点、代码执行、文件创建及终端界面的更新。Anthropic 在周一的新闻稿中宣布了这一消息。
Claude Code 新增了一个备受期待的功能——检查点,允许开发者保存进度或回退到之前的状态。此外,Claude 现在能够执行代码并创建文件,例如电子表格、幻灯片和文档。
在代理方面,Claude API 支持代理运行更长时间,处理更复杂的任务。通过 Claude Agent SDK,开发人员可以创建自己的 AI 代理,这些代理能更好地管理内存、处理权限,并与子代理协作以完成任务。
“我们的 Sonnet 模型支撑着大量的 AI 经济,无论是作为企业产品的一部分还是作为初创公司群背后的基础设施。”Anthropic 的首席人才官 Mike Krieger 在声明中表示,“每隔一段时间,我们就会推出一款我们认为将激发更多创造力的模型。Sonnet 4.5 就是这样一款模型。我们迫不及待地想看看人们会用它创造什么。”
Anthropic 称,Claude Sonnet 4.5 是他们发布的“最对齐前沿的模型”,意味着该模型在“阿谀奉承、欺骗行为、权力追求以及鼓励妄想思维”等方面有了显著改善。Anthropic 还声称,在抵御提示注入攻击方面取得了“重大进展”,这种攻击是指恶意行为者使用精心设计的语言诱骗模型执行其未被设计去做的事情。
iGent AI 的 CEO Sean Ward 在新闻稿中说:“Claude Sonnet 4.5 重置了我们的期望——它可以处理超过 30 小时的自主编码,使我们的工程师能够在大幅减少的时间内解决数月的复杂架构工作,同时在整个大型代码库中保持连贯性。”
随着 AI 竞赛的升温,Claude Sonnet 4.5 的发布恰逢其时。尽管 OpenAI 的 ChatGPT 和谷歌的 Gemini 吸引了大量关注,但像 Anthropic 这样的玩家也在推动 AI 技术的发展。Claude 因其编码能力和对话性质受到粉丝的喜爱。在由 OpenAI 开发的基准测试工具 GDPval 中,Claude Opus 4.1 表现最佳,超过了 GPT-5。这可能是导致 OpenAI 被发现使用 Claude Code 并因违反 Anthropic 的服务条款而失去访问权限的原因。OpenAI 回应称,评估竞争模型的准确性和安全性是行业标准做法,其 API 仍将继续向 Anthropic 提供。今年 8 月,两家公司公布了联合评估对方模型的结果。
(披露:CNET 的母公司 Ziff Davis 于 4 月对 OpenAI 提起诉讼,指控其在训练和运营 AI 系统时侵犯了 Ziff Davis 的版权。)
随着 Anthropic 在某些领域持续领先,该公司正在筹集数十亿美元的资金。最近,Anthropic 完成了 130 亿美元的 F 轮融资,估值达到 1830 亿美元。本月早些时候,Anthropic 还与作者们就非法盗版作品的 15 亿美元诉讼达成了和解。
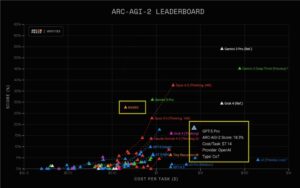
OSWorld 是一个测试 AI 模型在实际计算机任务中表现的工具,它对 Sonnet 4.5 的评分达到了 61.4%,而四个月前 Sonnet 4 的评分仅为 42.2%。目前,Claude for Chrome 扩展程序已经提供给上个月注册等待名单的用户,该扩展利用了 Sonnet 4.5 的代理功能改进。
(以上内容均由Ai生成)