Moondream3.0发布,多项测试超越GPT-5等顶尖模型
快速阅读: Moondream3.0预览版发布,基于高效混合专家架构,展现卓越视觉推理能力,轻量化设计下性能超越多个顶级模型,支持32K上下文长度及多种视觉技能,适用于实时交互和边缘计算。
在最新发布的Moondream3.0预览版中,这款基于高效混合专家(MoE)架构的模型展现了出色的视觉推理能力。尽管Moondream3.0拥有总计9亿参数,但通过仅激活2亿参数的轻量化设计,它在处理复杂场景时表现出色。与前一版本Moondream2相比,Moondream3.0在多个基准测试中超越了GPT-5、Gemini和Claude4等顶级模型,实现了技术上的重大突破。
Moondream3.0支持长达32K的上下文长度,非常适合实时交互和代理工作流程。该模型配备了创新的SigLIP视觉编码器,可处理高分辨率图像并支持多裁剪通道拼接。通过使用定制的高效SuperBPE分词器和多头注意力机制,模型在长上下文建模方面的能力显著提升。尽管其训练数据量约为450亿个令牌,远少于其他领先模型的万亿级别,但Moondream3.0仍能展现出色的性能。
这款模型的一大亮点在于其“全能”视觉技能,包括开放词汇的物体检测、点击选择、计数、字幕生成和光学字符识别(OCR)。它支持结构化输出,能够直接生成JSON数组,比如提取狗的ID、毛色和背带颜色等信息。此外,Moondream3.0在用户界面理解、文档转录和物体定位方面也有出色表现。
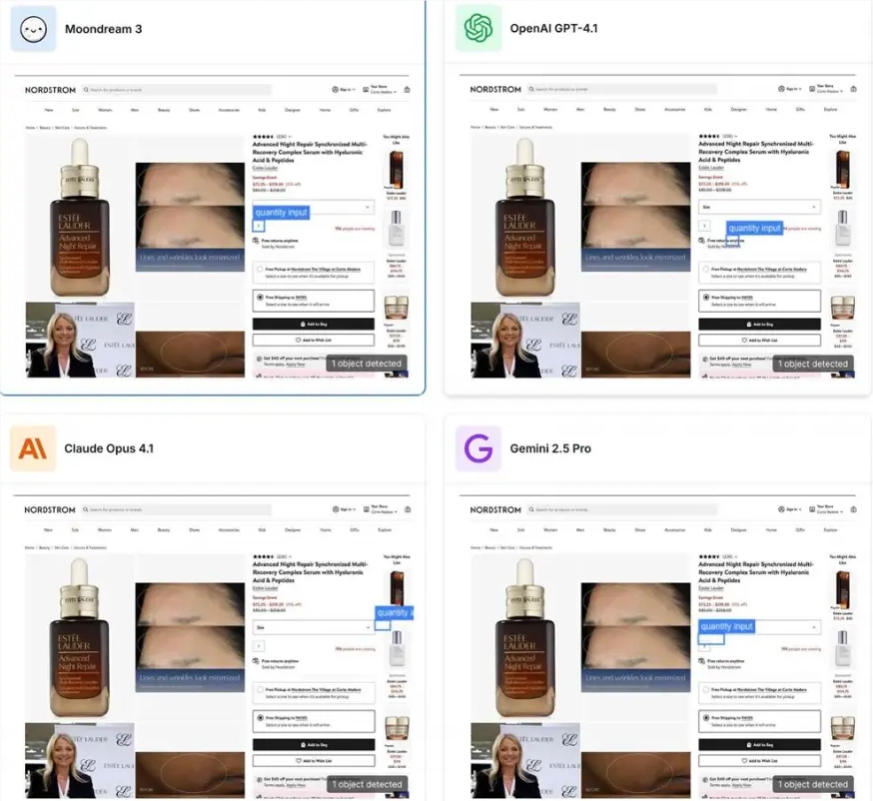
早期基准测试显示,Moondream3.0在COCO物体检测中的得分达到51.2,比前一代提高了20.7;在OCRBench上的得分从58.3升至61.2;ScreenSpot UI F1@0.5的得分为60.3。在实际应用中,该模型能够轻松识别复杂场景,如识别穿着紫色袜子的人、选择购物网页的数量输入框、标记瓶子以及推荐适合意大利面的餐具。其应用范围不仅涵盖安防监控和无人机巡检,还包括医学影像分析和企业级文档处理。
Moondream3.0是一款开源模型,秉持“无需训练、无需地面真相数据、无需重型基础设施”的理念。开发者只需简单的提示即可激活其强大的视觉理解能力。根据社区反馈,该模型已成功应用于机器人语义行为、移动设备和Raspberry Pi上,非常适合边缘计算环境。
(以上内容均由Ai生成)







