Exa Code发布,亿级代码索引助力AI编码无误
快速阅读: Exa Labs推出Exa Code,专为Coding Agent优化,通过索引超10亿页面提供精准代码上下文,显著降低LLM“幻觉”风险,现已免费开源,广受开发者欢迎。
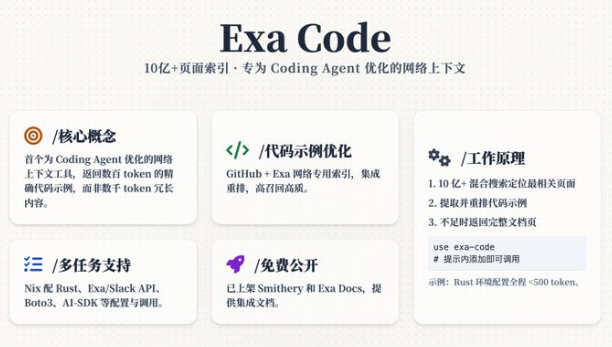
Exa Labs近期推出了Exa Code,一款专为Coding Agent优化的网络上下文工具。通过索引超过10亿个文档页面、GitHub仓库及Stack Overflow帖子,Exa Code提供高效、精准的代码上下文,帮助大型语言模型(LLM)避免生成错误代码。此工具在代码幻觉评估中表现优异,超越市面上所有网络搜索工具,包括Exa自家的产品。现已免费开源,迅速引起开发者社区的广泛关注。
Exa Code的核心创新点在于,它不是传统搜索工具的简单扩展,而是首款专为Coding Agent设计的解决方案。它摒弃了返回大量无关信息的低效模式,专注于提取高精度的相关token,通常只需几百个token即可涵盖核心内容,显著降低了LLM的“幻觉”风险。Exa Labs将Exa Code定位为最先进的产品,特别适用于编写新软件、配置应用环境或调用依赖项等场景。
例如,在提示中只需加入“use exa-code”指令,即可激活工具,帮助快速设置可复现的Rust开发环境,整个过程消耗token不足500个。这不仅提高了AI代理的可靠性,也为开发者节省了大量的调试时间。
Exa Code的关键特性包括:高效和实用为核心,集成多项创新功能:
– 精准上下文提取:优先从海量数据中筛选代码示例,避免数千token的冗长输出,确保信息密度最大化。
– 代码示例优化:基于GitHub和Exa网络索引构建专用数据库,使用集成检索方法重新排序示例,实现高召回率和高品质输出。
– 多任务支持:无缝适用于各种编程需求,如Nix配置Rust环境、Exa或Slack的API调用,以及AWS Boto3或AI-SDK等SDK使用。
– 免费集成:已在Smithery和Exa Docs平台公开发布,提供详尽文档,方便开发者快速接入,无需额外成本。
这些特性使Exa Code成为AI编码生态中的“瑞士军刀”,特别适合个人开发者或团队加速原型迭代。
Exa Code的工作原理简洁高效,仅需三步即可完成上下文生成:
1. 混合搜索启动:在超过10亿网页中执行混合检索,锁定最相关的页面。
2. 代码提取与排序:从页面中抽取代码示例,并通过集成方法进行智能重排序,确保最高优先级的内容显现。
3. 智能输出:当示例充足时,拼接成高效的字符串返回;否则,提供完整的文档页面(如API说明),以确保全面性。
这种设计不仅减少了token浪费,还提高了响应的实时性,使Coding Agent在复杂任务中表现出色。
Exa Code的最大价值在于重塑AI代码生成的可靠性。通过独立评估,该工具在解决幻觉问题方面远超其他上下文工具,同时保持最低的token消耗,支持多样化的库和API处理。开发者从中受益:AI辅助编码更加可靠,用户能够实现更高水平的软件生成。
Exa Labs强调:“想象一下,如果LLM从不产生幻觉——它们将以极高的能力编写新软件并调用依赖项。”这一愿景已通过实际测试得以验证,Exa Code正推动AI从“辅助工具”向“独立开发者”的转变。
展望AI编码的新时代,Exa Code的发布标志着AI搜索工具向专业化发展的重要一步。随着开源社区的参与,这一工具有望进一步迭代,促进更多创新应用的诞生。
官方介绍:https://exa.ai/blog/exa-code
(以上内容均由Ai生成)







